The new Amazon Elastic Compute Cloud (Amazon EC2) Trn2 instances and Trn2 UltraServers are the most powerful EC2 compute options for ML training and inference. Powered by the second generation of AWS Trainium chips (AWS Trainium2), the Trn2 instances are 4x faster, offer 4x more memory bandwidth, and 3x more memory capacity than the first-generation Trn1 instances. Trn2 instances offer 30-40% better price performance than the current generation of GPU-based EC2 P5e and P5en instances.
In addition to the 16 Trainium2 chips, each Trn2 instance features 192 vCPUs, 2 TiB of memory, and 3.2 Tbps of Elastic Fabric Adapter (EFA) v3 network bandwidth, which offers up to 35% lower latency than the previous generation.
The Trn2 UltraServers, which are a completely new compute offering, feature 64x Trainium2 chips connected with a high-bandwidth, low-latency NeuronLink interconnect, for peak inference and training performance on frontier foundation models.
Tens of thousands of Trainium chips are already powering Amazon and AWS services. For example, over 80,000 AWS Inferentia and Trainium1 chips supported the Rufus shopping assistant on the most recent Prime Day. Trainium2 chips are already powering the latency-optimized versions of Llama 3.1 405B and Claude 3.5 Haiku models on Amazon Bedrock.
Up and Out and Up
Sustained growth in the size and complexity of the frontier models is enabled by innovative forms of compute power, assembled into equally innovative architectural forms. In simpler times we could talk about architecting for scalability in two ways: scaling up (using a bigger computer) and scaling out (using more computers). Today, when I look at the Trainium2 chip, the Trn2 instance, and the even larger compute offerings that I will talk about in a minute, it seems like both models apply, but at different levels of the overall hierarchy. Let’s review the Trn2 building blocks, starting at the NeuronCore and scaling to an UltraCluster:
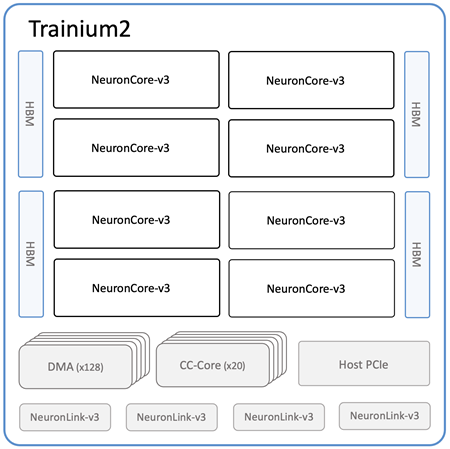 NeuronCores are at the heart of the Trainium2 chip. Each third-generation NeuronCore includes a scalar engine (1 input to 1 output), a vector engine (multiple inputs to multiple outputs), a tensor engine (systolic array multiplication, convolution, and transposition), and a GPSIMD (general purpose single instruction multiple data) core.
NeuronCores are at the heart of the Trainium2 chip. Each third-generation NeuronCore includes a scalar engine (1 input to 1 output), a vector engine (multiple inputs to multiple outputs), a tensor engine (systolic array multiplication, convolution, and transposition), and a GPSIMD (general purpose single instruction multiple data) core.
Each Trainium2 chip is home to eight NeuronCores and 96 GiB of High Bandwidth Memory (HBM), and supports 2.9 TB/second of HBM bandwidth. The cores can be addressed and used individually, or pairs of physical cores can be grouped into a single logical core. A single Trainium2 chip delivers up to 1.3 petaflops of dense FP8 compute and up to 5.2 petaflops of sparse FP8 compute, and can drive 95% utilization of memory bandwidth thanks to automated reordering of the HBM queue.
Each Trn2 instance is, in turn, home to 16 Trainum2 chips. That’s a total of 128 NeuronCores, 1.5 TiB of HBM, and 46 TB/second of HBM bandwidth. Altogether this multiplies out to up to 20.8 petaflops of dense FP8 compute and up to 83.2 petaflops of sparse FP8 compute. The Trainium2 chips are connected across NeuronLink in a 2D torus for high bandwidth, low latency chip-to-chip communication at 1 GB/second.
An UltraServer is home to four Trn2 instances connected with low-latency, high-bandwidth NeuronLink. That’s 512 NeuronCores, 64 Trainium2 chips, 6 TiB of HBM, and 185 TB/second of HBM bandwidth. Doing the math, this results in up to 83 petaflops of dense FP compute and up to 332 petaflops of sparse FP8 compute. In addition to the 2D torus that connects NeuronCores within an instance, Cores at corresponding XY positions in each of the four instances are connected in a ring. For inference, UltraServers help deliver industry-leading response time to create the best real-time experiences. For training, UltraServers boost model training speed and efficiency with faster collective communication for model parallelism when compared to standalone instances. UltraServers are designed to support training and inference at the trillion parameter level and beyond; they are available in preview form and you can contact us to join the preview.
Trn2 instances and UltraServers are being deployed in EC2 UltraClusters to enable scale-out distributed training across tens of thousands of Trainium chips on a single petabit scale, non-blocking network, with access to Amazon FSx for Lustre high performance storage.
Using Trn2 Instances
Trn2 instances are available today for production use in the US East (Ohio) AWS Region and can be reserved by using Amazon EC2 Capacity Blocks for ML. You can reserve up to 64 instances for up to six months, with reservations accepted up to eight weeks in advance, with instant start times and the ability to extend your reservations if needed. To learn more, read Announcing Amazon EC2 Capacity Blocks for ML to reserve GPU capacity for your machine learning workloads.
On the software side, you can start with the AWS Deep Learning AMIs. These images are preconfigured with the frameworks and tools that you probably already know and use: PyTorch, JAX, and a lot more.
If you used the AWS Neuron SDK to build your apps, you can bring them over and recompile them for use on Trn2 instances. This SDK integrates natively with JAX, PyTorch, and essential libraries like Hugging Face, PyTorch Lightning, and NeMo. Neuron includes out-of-the-box optimizations for distributed training and inference with the open source PyTorch libraries NxD Training and NxD Inference, while providing deep insights for profiling and debugging. Neuron also supports OpenXLA, including stable HLO and GSPMD, enabling PyTorch/XLA and JAX developers to utilize Neuron’s compiler optimizations for Trainium2.
— Jeff;