Amazon S3 Tables give you storage that is optimized for tabular data such as daily purchase transactions, streaming sensor data, and ad impressions in Apache Iceberg format, for easy queries using popular query engines like Amazon Athena, Amazon EMR, and Apache Spark. When compared to self-managed table storage, you can expect up to 3x faster query performance and up to 10x more transactions per second, along with the operational efficiency that is part-and-parcel when you use a fully managed service.
Iceberg has become the most popular way to manage Parquet files, with thousands of AWS customers using Iceberg to query across often billions of files containing petabytes or even exabytes of data.
Table Buckets, Tables, and Namespaces Table buckets are the third type of S3 bucket, taking their place alongside the existing general purpose and directory buckets. You can think of a table bucket as an analytics warehouse that can store Iceberg tables with various schemas. Additionally, S3 Tables deliver the same durability, availability, scalability, and performance characteristics as S3 itself, and automatically optimize your storage to maximize query performance and to minimize cost.
Table buckets are the third type of S3 bucket, taking their place alongside the existing general purpose and directory buckets. You can think of a table bucket as an analytics warehouse that can store Iceberg tables with various schemas. Additionally, S3 Tables deliver the same durability, availability, scalability, and performance characteristics as S3 itself, and automatically optimize your storage to maximize query performance and to minimize cost.
Each table bucket resides in a specific AWS Region and has a name that must be unique within the AWS account with respect to the region. Buckets are referenced by ARN and also have a resource policy. Finally, each bucket uses namespaces to logically group the tables in the bucket.
Tables are structured datasets stored in a table bucket. Like table buckets, they have ARNs and resource policies, and exist within one of the bucket’s namespaces. Tables are fully managed, with automatic, configurable continuous maintenance including compaction, management of aged snapshots, and removal of unreferenced files. Each table has an S3 API endpoint for storage operations.
Namespaces can be referenced from access policies in order to simplify access management.
Buckets and Tables from the Command Line
Ok, let’s dive right in, create a bucket, and put a table or two inside. I’ll use the AWS Command Line Interface (AWS CLI), but AWS Management Console and API support is also available. For conciseness, I will pipe the output of the more verbose commands through jq and show you only the most relevant values.
The first step is to create a table bucket:
For convenience, I create an environment variable with the ARN of the table bucket:
And then I list my table buckets:
I can access and populate the table in many different ways. For testing purposes I installed Apache Spark, then invoked the Spark shell with command-line arguments to use the Amazon S3 Tables Catalog for Apache Iceberg package and to set mytablebucket to the ARN of my table.
I create a namespace (mydata) that I will use to group my tables:
Then I create a simple Iceberg table in the namespace:
I use somes3tables commands to check my work:
Then I return to the Spark shell and add a few rows of data to my table:
Buckets and Tables from the Console
I can also create and work on table buckets using the S3 Console. I click Table buckets to get started:
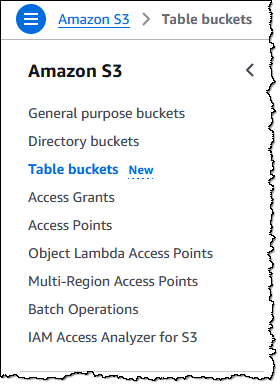
Before creating my first bucket I click Enable integration so that I can access my table buckets from Amazon Athena, Amazon Redshift, Amazon EMR, and other AWS query engines (I can do this later if I don’t do it now):
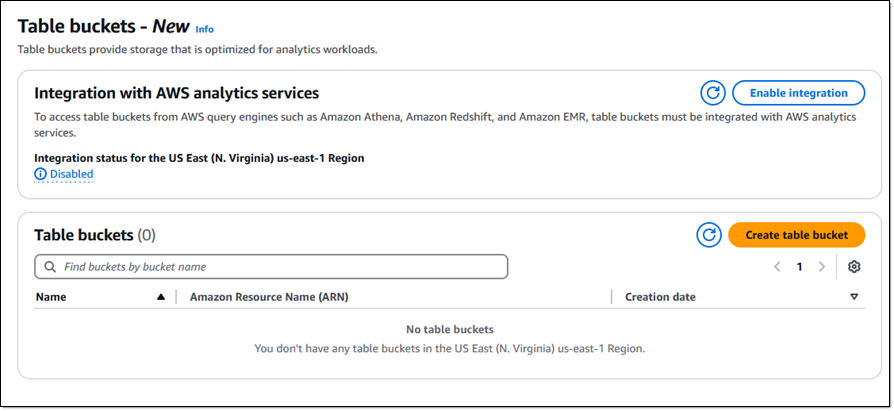
I read the fine print and click Enable integration to create the specified IAM role and an entry in the AWS Glue Data Catalog:
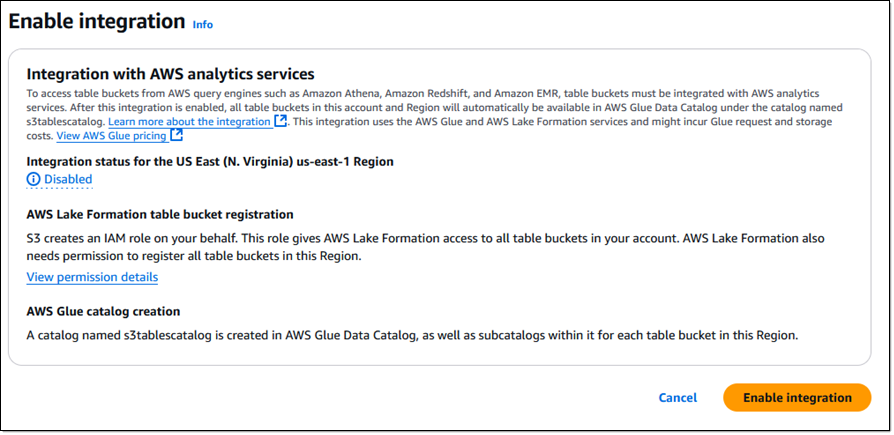
After a few seconds the integration is enabled and I click Create table bucket to move ahead:
I enter a name (jbarr-table-bucket-3) and click Create table bucket:
From here I can create and use tables as I showed you earlier in the CLI section.
Table Maintenance
Table buckets take care of some important maintenance duties that would be your responsibility if you were creating and managing your own Iceberg tables. To relieve you of these duties so that you can spend more time on your table, the following maintenance operations are performed automatically:
Compaction – This process combines multiple small table objects into a larger object to improve query performance, in pursuit of a target file size that can be configured to be between 64 MiB and 512 MiB. The new object is rewritten as a new snapshot.
Snapshot Management – This process expires and ultimately removes table snapshots, with configuration options for the minimum number of snapshots to retain and the maximum age of a snapshot to retain. Expired snapshots are marked as non-current, then later deleted after a specified number of days.
Unreferenced File Removal – This process removes and deletes objects that are not referenced by any table snapshots.
Things to Know
Here are a couple of important things that you should know about table buckets and tables:
AWS Integration – S3 Tables integration with AWS Glue Data Catalog is in preview, allowing you to query and visualize data using AWS Analytics services such as Amazon Athena, Amazon Redshift, Amazon EMR, and Amazon QuickSight.
S3 API Support – Table buckets support relevant S3 API functions including GetObject, HeadObject, PutObject, and the multi-part upload operations.
Security – All objects stored in table buckets are automatically encrypted. Table buckets are configured to enforce Block Public Access.
Pricing – You pay for storage, requests, an object monitoring fee, and and fees for compaction. See the S3 Pricing page for more info.
Regions – You can use this new feature in the US East (Ohio, N. Virginia) and US West (Oregon) AWS Regions.
— Jeff;