 AWS customers make use of Amazon Simple Storage Service (Amazon S3) at an incredible scale, regularly creating individual buckets that contain billions or trillions of objects! At that scale, finding the objects which meet particular criteria — objects with keys that match a pattern, objects of a particular size, or objects with a specific tag — becomes challenging. Our customers have had to build systems that capture, store, and query for this information. These systems can become complex and hard to scale, and can fall out of sync with the actual state of the bucket and the objects within.
AWS customers make use of Amazon Simple Storage Service (Amazon S3) at an incredible scale, regularly creating individual buckets that contain billions or trillions of objects! At that scale, finding the objects which meet particular criteria — objects with keys that match a pattern, objects of a particular size, or objects with a specific tag — becomes challenging. Our customers have had to build systems that capture, store, and query for this information. These systems can become complex and hard to scale, and can fall out of sync with the actual state of the bucket and the objects within.
Rich Metadata
Today we are enabling in preview automatic generation of metadata that is captured when S3 objects are added or modified, and stored in fully managed Apache Iceberg tables. This allows you to use Iceberg-compatible tools such as Amazon Athena, Amazon Redshift, Amazon QuickSight, and Apache Spark to easily and efficiently query the metadata (and find the objects of interest) at any scale. As a result, you can quickly find the data that you need for your analytics, data processing, and AI training workloads.
For video inference responses stored in S3, Amazon Bedrock will annotate the content it generates with metadata that will allow you to identify the content as AI-generated, and to know which model was used to generate it.
The metadata schema contains over 20 elements including the bucket name, object key, creation/modification time, storage class, encryption status, tags, and user metadata. You can also store additional, application-specific descriptive information in a separate table and then join it with the metadata table as part of your query.
How it Works
You can enable capture of rich metadata for any of your S3 buckets by specifying the location (an S3 table bucket and a table name) where you want the metadata to be stored. Capture of updates (object creations, object deletions, and changes to object metadata) begins right away and will be stored in the table within minutes. Each update generates a new row in the table, with a record type (CREATE, UPDATE_METADATA, or DELETE) and a sequence number. You can retrieve the historical record for a given object by running a query that orders the results by sequence number.
Enabling and Querying Metadata
I start by creating a table bucket for my metadata using the create-table-bucket command (this can also be done from the AWS Management Console or with an API call):
Then I specify the table bucket (by ARN) and the desired table name by putting this JSON into a file (I’ll call it config.json):
And then I attach this configuration to my data bucket (the one that I want to capture metadata for):
For testing purposes I installed Apache Spark on an EC2 instance and after a little bit of setup I was able to run queries by referencing the Amazon S3 Tables Catalog for Apache Iceberg package and adding the metadata table (as mytablebucket) to the command line:
Here is the current schema for the Iceberg table:
Here’s a simple query that shows some of the metadata for the ten most recent updates:
In a real-world situation I would query the table using one of the AWS or open source analytics tools that I mentioned earlier.
Console Access
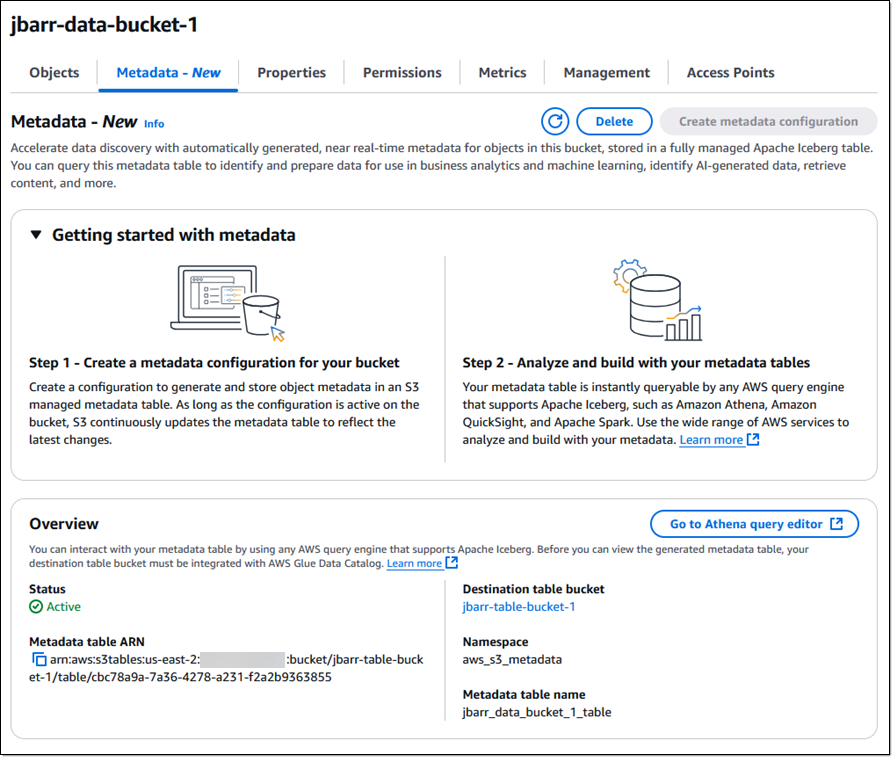
I can also set up and manage the metadata configuration for my buckets using the Amazon S3 Console by clicking the Metadata tab:
Available Now
Amazon S3 Metadata is available in preview now and you can start using it today in the US East (Ohio, N. Virginia) and US West (Oregon) AWS Regions.
Integration with AWS Glue Data Catalog is in preview, allowing you to query and visualize data—including S3 Metadata tables—using AWS Analytics services such as Amazon Athena, Amazon Redshift, Amazon EMR, and Amazon QuickSight.
Pricing is based on the number updates (object creations, object deletions, and changes to object metadata) with an additional charge for storage of the metadata table. For more pricing information, visit the S3 Pricing page.
I’m confident that you will be able to make use of this metadata in many powerful ways, and am looking forward to hearing about your use cases. Let me know what you think!
— Jeff;