Today, I’m very excited to announce the general availability of Amazon SageMaker Lakehouse, a capability that unifies data across Amazon Simple Storage Service (Amazon S3) data lakes and Amazon Redshift data warehouses, helping you build powerful analytics and artificial intelligence and machine learning (AI/ML) applications on a single copy of data. SageMaker Lakehouse is a part of the next generation of Amazon SageMaker, which is a unified platform for data, analytics and AI, that brings together widely-adopted AWS machine learning and analytics capabilities and delivers an integrated experience for analytics and AI.
Customers want to do more with data. To move faster with their analytics journey, they are picking the right storage and databases to store their data. The data is spread across data lakes, data warehouses, and different applications, creating data silos that make it difficult to access and utilize. This fragmentation leads to duplicate data copies and complex data pipelines, which in turn increases costs for the organization. Furthermore, customers are constrained to use specific query engines and tools, as the way and where the data is stored limits their options. This restriction hinders their ability to work with the data as they would prefer. Lastly, the inconsistent data access makes it challenging for customers to make informed business decisions.
SageMaker Lakehouse addresses these challenges by helping you to unify data across Amazon S3 data lakes and Amazon Redshift data warehouses. It offers you the flexibility to access and query data in-place with all engines and tools compatible with Apache Iceberg. With SageMaker Lakehouse, you can define fine-grained permissions centrally and enforce them across multiple AWS services, simplifying data sharing and collaboration. Bringing data into your SageMaker Lakehouse is easy. In addition to seamlessly accessing data from your existing data lakes and data warehouses, you can use zero-ETL from operational databases such as Amazon Aurora, Amazon RDS for MySQL, Amazon DynamoDB, as well as applications such as Salesforce and SAP. SageMaker Lakehouse fits into your existing environments.
Get started with SageMaker Lakehouse
For this demonstration, I use a preconfigured environment that has multiple AWS data sources. I go to the Amazon SageMaker Unified Studio (preview) console, which provides an integrated development experience for all your data and AI. Using Unified Studio, you can seamlessly access and query data from various sources through SageMaker Lakehouse, while using familiar AWS tools for analytics and AI/ML.
This is where you can create and manage projects, which serve as shared workspaces. These projects allow team members to collaborate, work with data, and develop AI models together. Creating a project automatically sets up AWS Glue Data Catalog databases, establishes a catalog for Redshift Managed Storage (RMS) data, and provisions necessary permissions. You can get started by creating a new project or continue with an existing project.
To create a new project, I choose Create project.

I have 2 project profile options to build a lakehouse and interact with it. First one is Data analytics and AI-ML model development, where you can analyze data and build ML and generative AI models powered by Amazon EMR, AWS Glue, Amazon Athena, Amazon SageMaker AI, and SageMaker Lakehouse. Second one is SQL analytics, where you can analyze your data in SageMaker Lakehouse using SQL. For this demo, I proceed with SQL analytics.
I enter a project name in the Project name field and choose SQL analytics under Project profile. I choose Continue.

I enter the values for all the parameters under Tooling. I enter the values to create my Lakehouse databases. I enter the values to create my Redshift Serverless resources. Finally, I enter a name for my catalog under Lakehouse Catalog.

On the next step, I review the resources and choose Create project.

After the project is created, I observe the project details.

I go to Data in the navigation pane and choose the + (plus) sign to Add data. I choose Create catalog to create a new catalog and choose Add data.

After the RMS catalog is created, I choose Build from the navigation pane and then choose Query Editor under Data Analysis & Integration to create a schema under RMS catalog, create a table, and then load table with sample sales data.

After entering the SQL queries into the designated cells, I choose Select data source from the right dropdown menu to establish a database connection to Amazon Redshift data warehouse. This connection allows me to execute the queries and retrieve the desired data from the database.

Once the database connection is successfully established, I choose Run all to execute all queries and monitor the execution progress until all results are displayed.

For this demonstration, I use two additional pre-configured catalogs. A catalog is a container that organizes your lakehouse object definitions such as schema and tables. The first is an Amazon S3 data lake catalog (test-s3-catalog) that stores customer records, containing detailed transactional and demographic information. The second is a lakehouse catalog (churn_lakehouse) dedicated to storing and managing customer churn data. This integration creates a unified environment where I can analyze customer behavior alongside churn predictions.
From the navigation pane, I choose Data and locate my catalogs under the Lakehouse section. SageMaker Lakehouse offers multiple analysis options, including Query with Athena, Query with Redshift, and Open in Jupyter Lab notebook.
Note that you need to choose Data analytics and AI-ML model development profile when you create a project, if you want to use Open in Jupyter Lab notebook option. If you choose Open in Jupyter Lab notebook, you can interact with SageMaker Lakehouse using Apache Spark via EMR 7.5.0 or AWS Glue 5.0 by configuring the Iceberg REST catalog, enabling you to process data across your data lakes and data warehouses in a unified manner.

Here’s how querying using Jupyter Lab notebook looks like:

I continue by choosing Query with Athena. With this option, I can use serverless query capability of Amazon Athena to analyze the sales data directly within SageMaker Lakehouse. Upon selecting Query with Athena, the Query Editor launches automatically, providing an workspace where I can compose and execute SQL queries against the lakehouse. This integrated query environment offers a seamless experience for data exploration and analysis, complete with syntax highlighting and auto-completion features to enhance productivity.
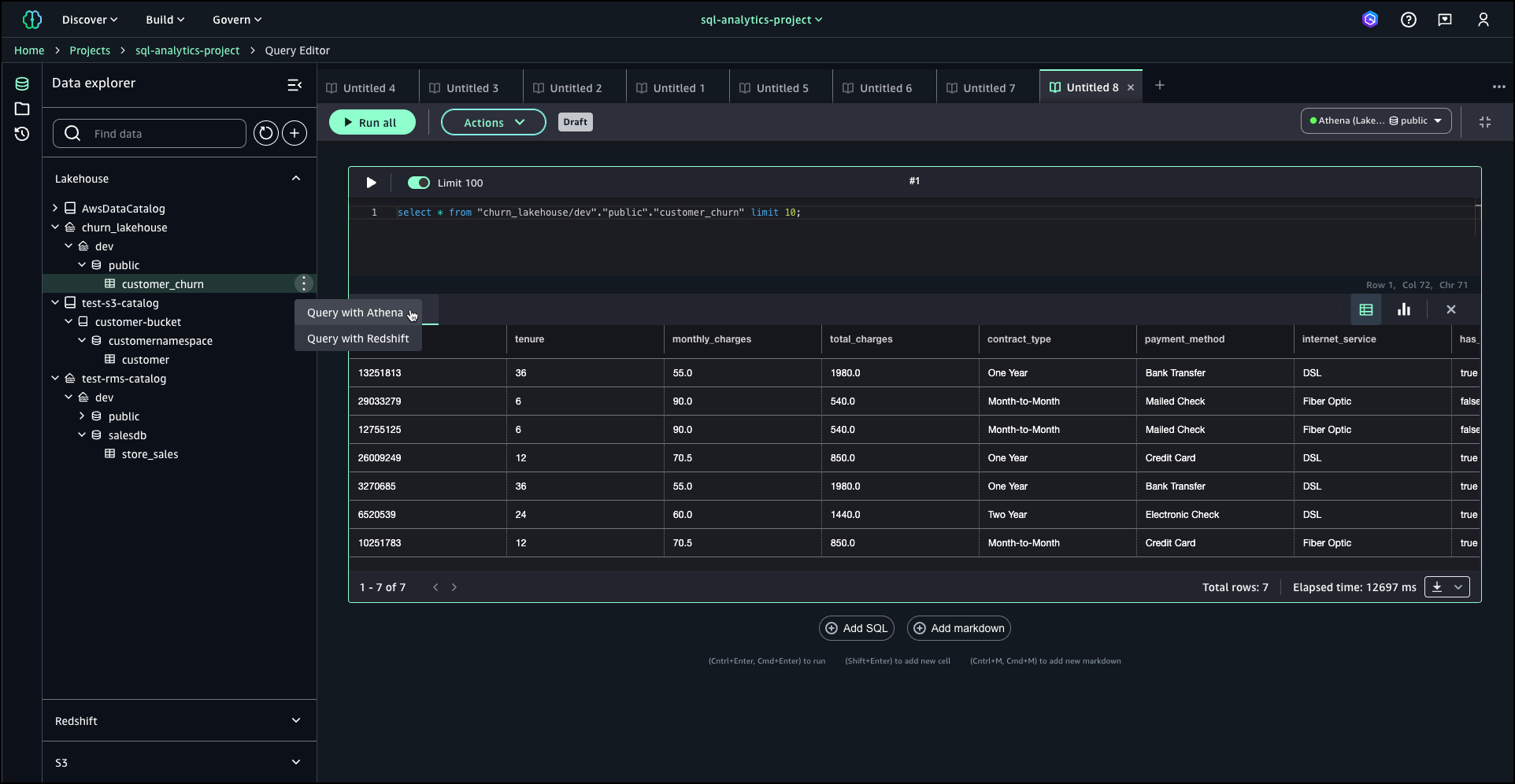
I can also use Query with Redshift option to run SQL queries against the lakehouse.

SageMaker Lakehouse offers a comprehensive solution for modern data management and analytics. By unifying access to data across multiple sources, supporting a wide range of analytics and ML engines, and providing fine-grained access controls, SageMaker Lakehouse helps you make the most of your data assets. Whether you’re working with data lakes in Amazon S3, data warehouses in Amazon Redshift, or operational databases and applications, SageMaker Lakehouse provides the flexibility and security you need to drive innovation and make data-driven decisions. You can use hundreds of connectors to integrate data from various sources. Additionally, you can access and query data in-place with federated query capabilities across third-party data sources.
Now available
You can access SageMaker Lakehouse through the AWS Management Console, APIs, AWS Command Line Interface (AWS CLI), or AWS SDKs. You can also access through AWS Glue Data Catalog and AWS Lake Formation. SageMaker Lakehouse is available in US East (N. Virginia), US West (Oregon), US East (Ohio), Europe (Ireland), Europe (Frankfurt), Europe (Stockholm), Asia Pacific (Sydney), Asia Pacific (Hong Kong), Asia Pacific (Tokyo), and Asia Pacific (Singapore) AWS Regions.
For pricing information, visit the Amazon SageMaker pricing.
For more information on Amazon SageMaker Lakehouse and how it can simplify your data analytics and AI/ML workflows, visit the Amazon SageMaker Lakehouse documentation.