At re:Invent 2024, we launched Amazon S3 Tables, the first cloud object store with built-in Apache Iceberg support to streamline storing tabular data at scale, and Amazon SageMaker Lakehouse to simplify analytics and AI with a unified, open, and secure data lakehouse. We also previewed S3 Tables integration with Amazon Web Services (AWS) analytics services for you to stream, query, and visualize S3 Tables data using Amazon Athena, Amazon Data Firehose, Amazon EMR, AWS Glue, Amazon Redshift, and Amazon QuickSight.
Our customers wanted to simplify the management and optimization of their Apache Iceberg storage, which led to the development of S3 Tables. They were simultaneously working to break down data silos that impede analytics collaboration and insight generation using the SageMaker Lakehouse. When paired with S3 Tables and SageMaker Lakehouse in addition to built-in integration with AWS analytics services, they can gain a comprehensive platform unifying access to multiple data sources enabling both analytics and machine learning (ML) workflows.
Today, we’re announcing the general availability of Amazon S3 Tables integration with Amazon SageMaker Lakehouse to provide unified S3 Tables data access across various analytics engines and tools. You can access SageMaker Lakehouse from Amazon SageMaker Unified Studio, a single data and AI development environment that brings together functionality and tools from AWS analytics and AI/ML services. All S3 tables data integrated with SageMaker Lakehouse can be queried from SageMaker Unified Studio and engines such as Amazon Athena, Amazon EMR, Amazon Redshift, and Apache Iceberg-compatible engines like Apache Spark or PyIceberg.
With this integration, you can simplify building secure analytic workflows where you can read and write to S3 Tables and join with data in Amazon Redshift data warehouses and third-party and federated data sources, such as Amazon DynamoDB or PostgreSQL.
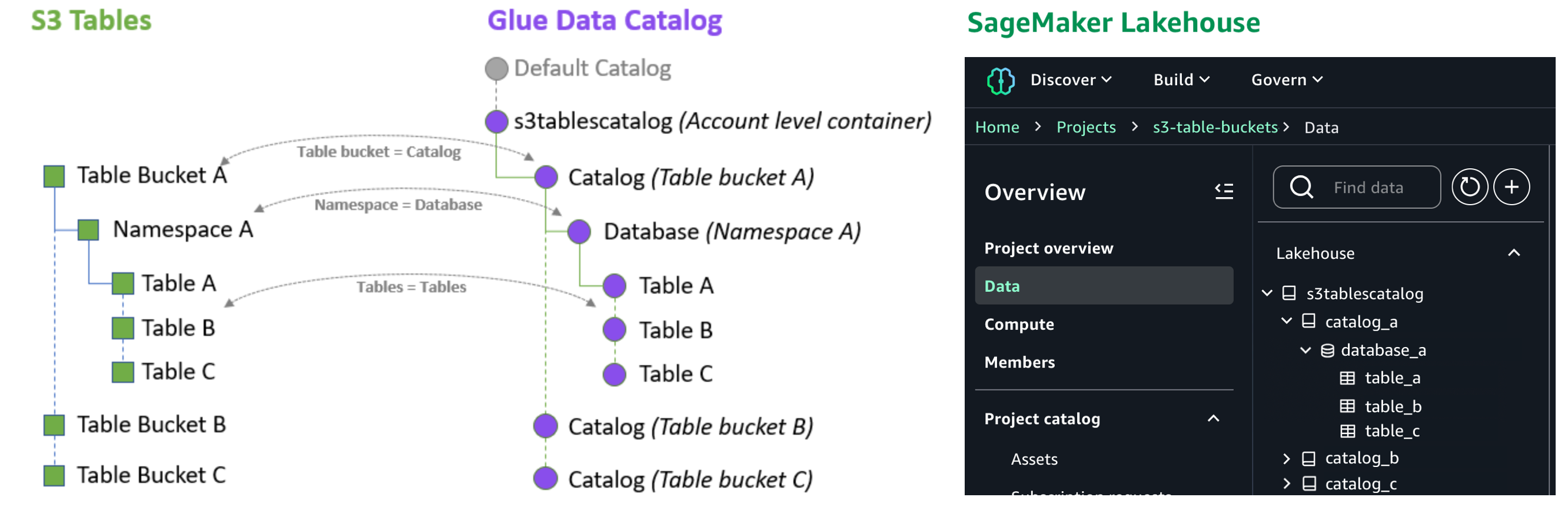
You can also centrally set up and manage fine-grained access permissions on the data in S3 Tables along with other data in the SageMaker Lakehouse and consistently apply them across all analytics and query engines.
S3 Tables integration with SageMaker Lakehouse in action
To get started, go to the Amazon S3 console and choose Table buckets from the navigation pane and select Enable integration to access table buckets from AWS analytics services.
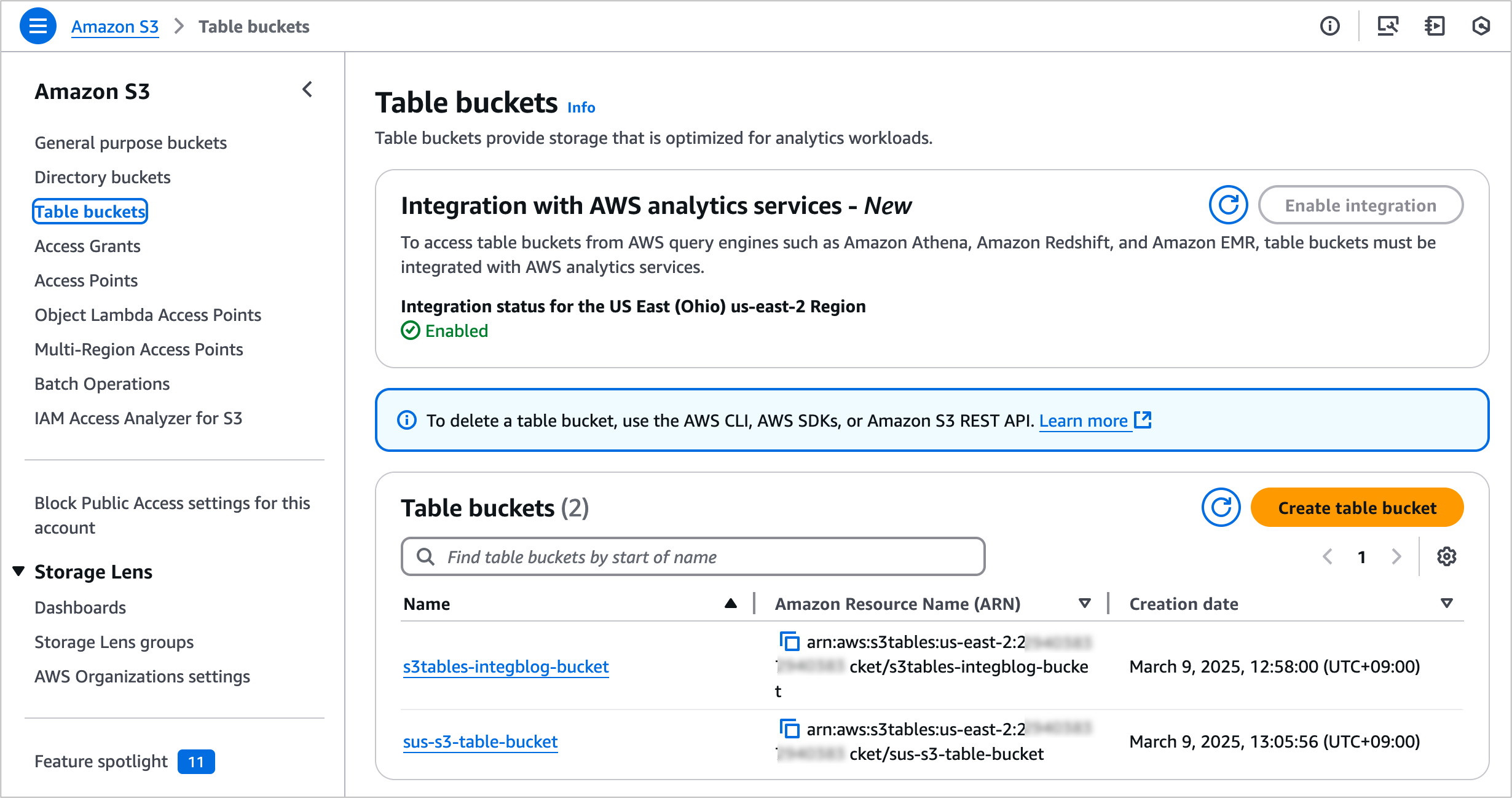
Now you can create your table bucket to integrate with SageMaker Lakehouse. To learn more, visit Getting started with S3 Tables in the AWS documentation.
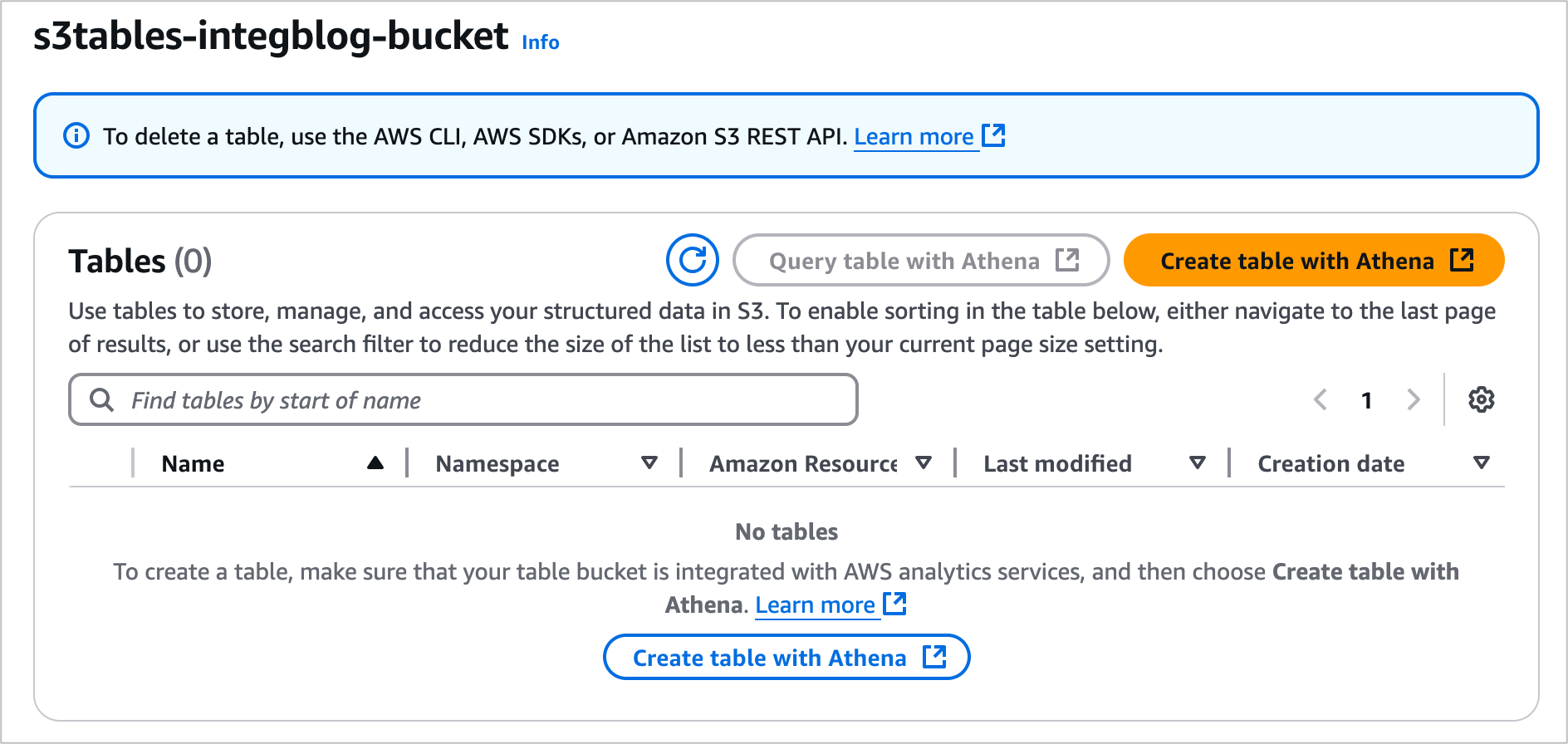
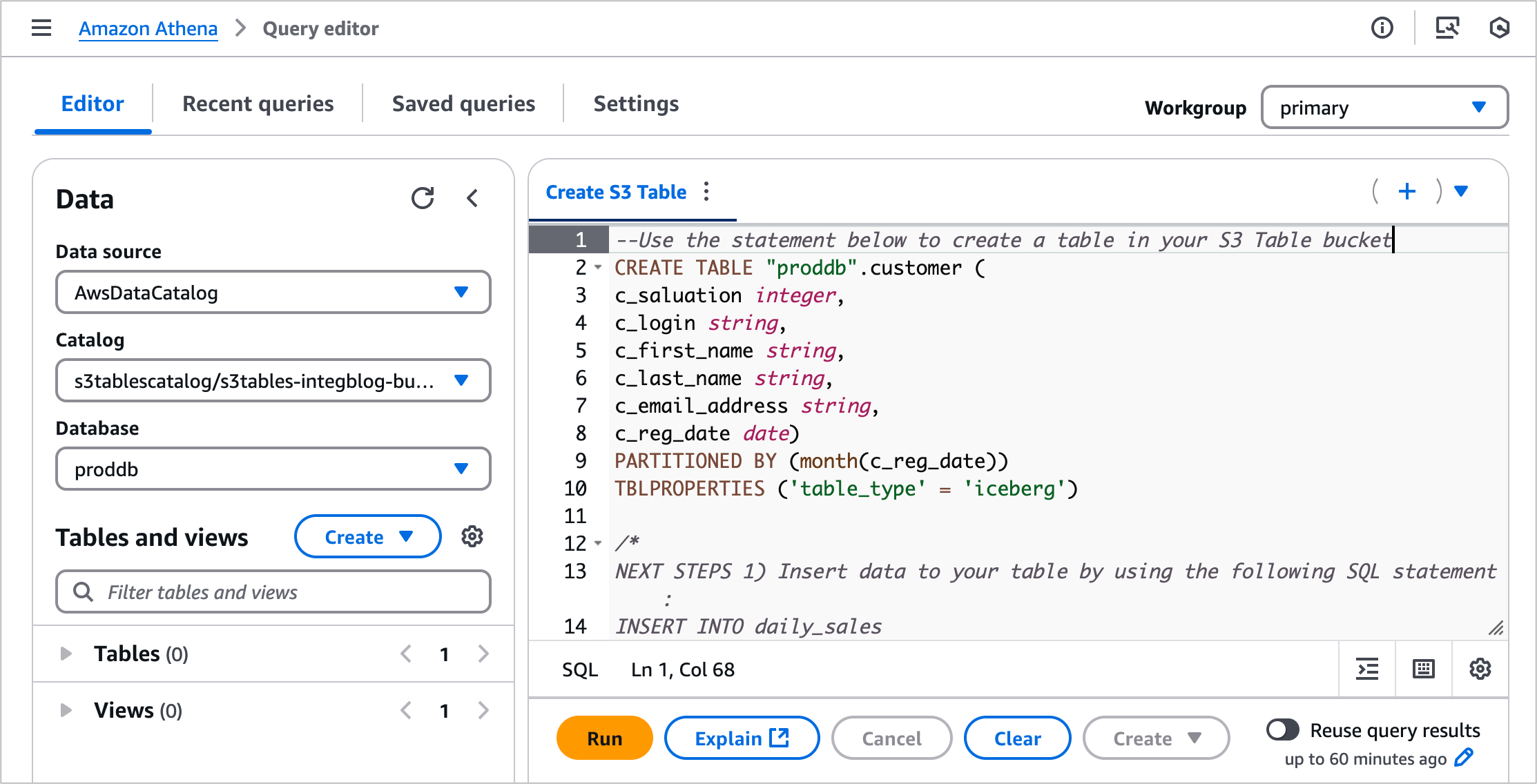
1. Create a table with Amazon Athena in the Amazon S3 console
You can create a table, populate it with data, and query it directly from the Amazon S3 console using Amazon Athena with just a few steps. Select a table bucket and select Create table with Athena, or you can select an existing table and select Query table with Athena.
When you want to create a table with Athena, you should first specify a namespace for your table. The namespace in an S3 table bucket is equivalent to a database in AWS Glue, and you use the table namespace as the database in your Athena queries.
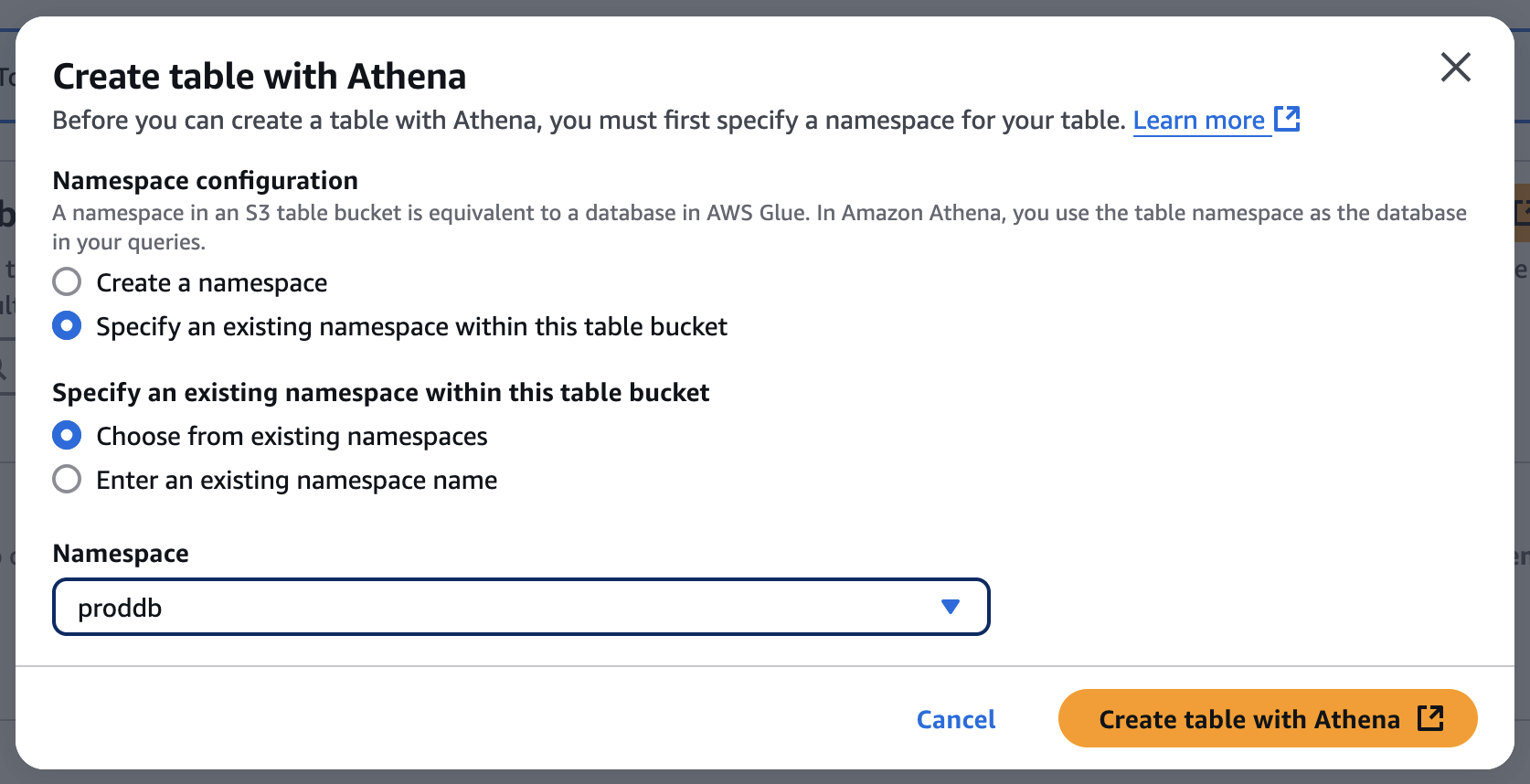
Choose a namespace and select Create table with Athena. It goes to the Query editor in the Athena console. You can create a table in your S3 table bucket or query data in the table.
2. Query with SageMaker Lakehouse in the SageMaker Unified Studio
Now you can access unified data across S3 data lakes, Redshift data warehouses, third-party and federated data sources in SageMaker Lakehouse directly from SageMaker Unified Studio.
To get started, go to the SageMaker console and create a SageMaker Unified Studio domain and project using a sample project profile: Data Analytics and AI-ML model development. To learn more, visit Create an Amazon SageMaker Unified Studio domain in the AWS documentation.
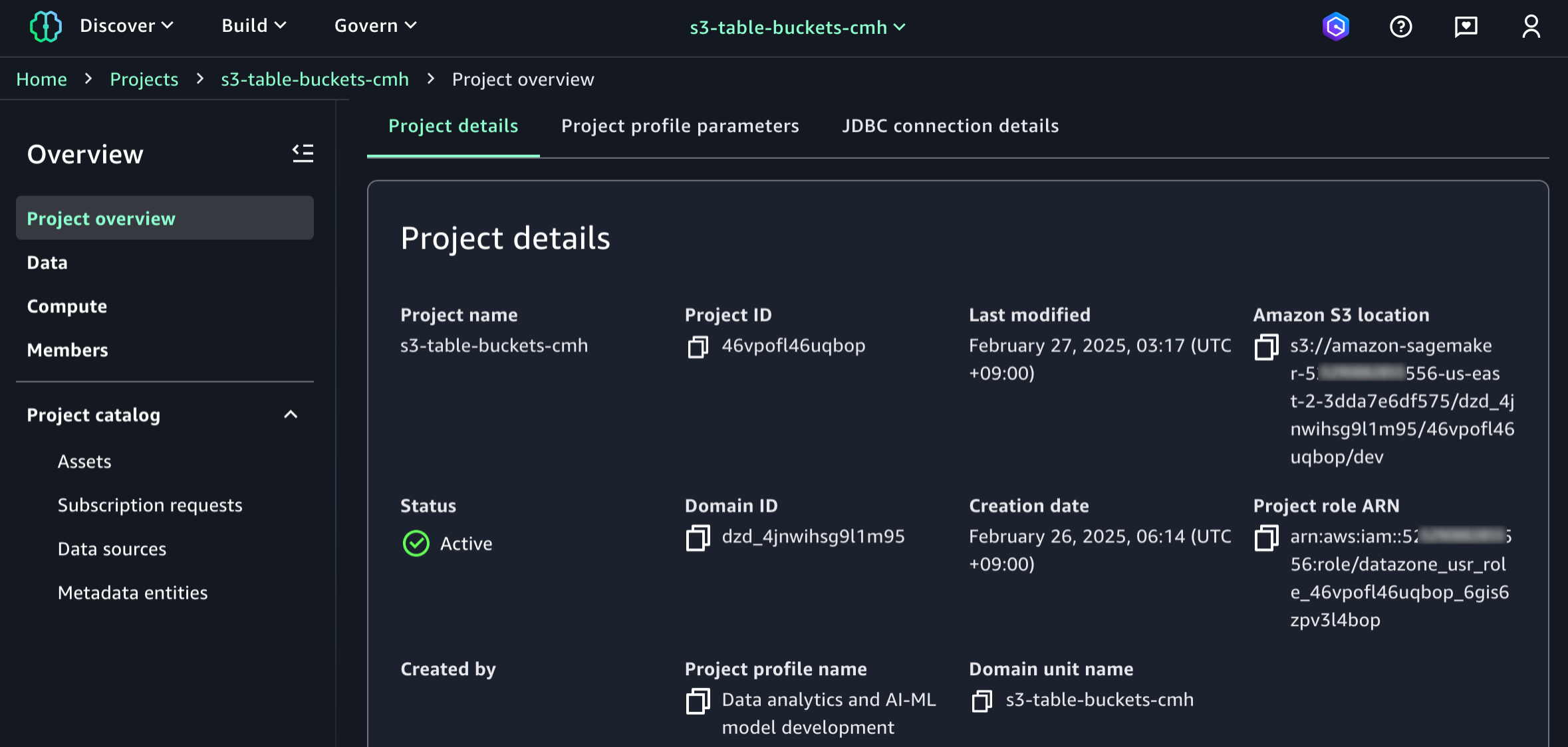
After the project is created, navigate to the project overview and scroll down to project details to note down the project role Amazon Resource Name (ARN).
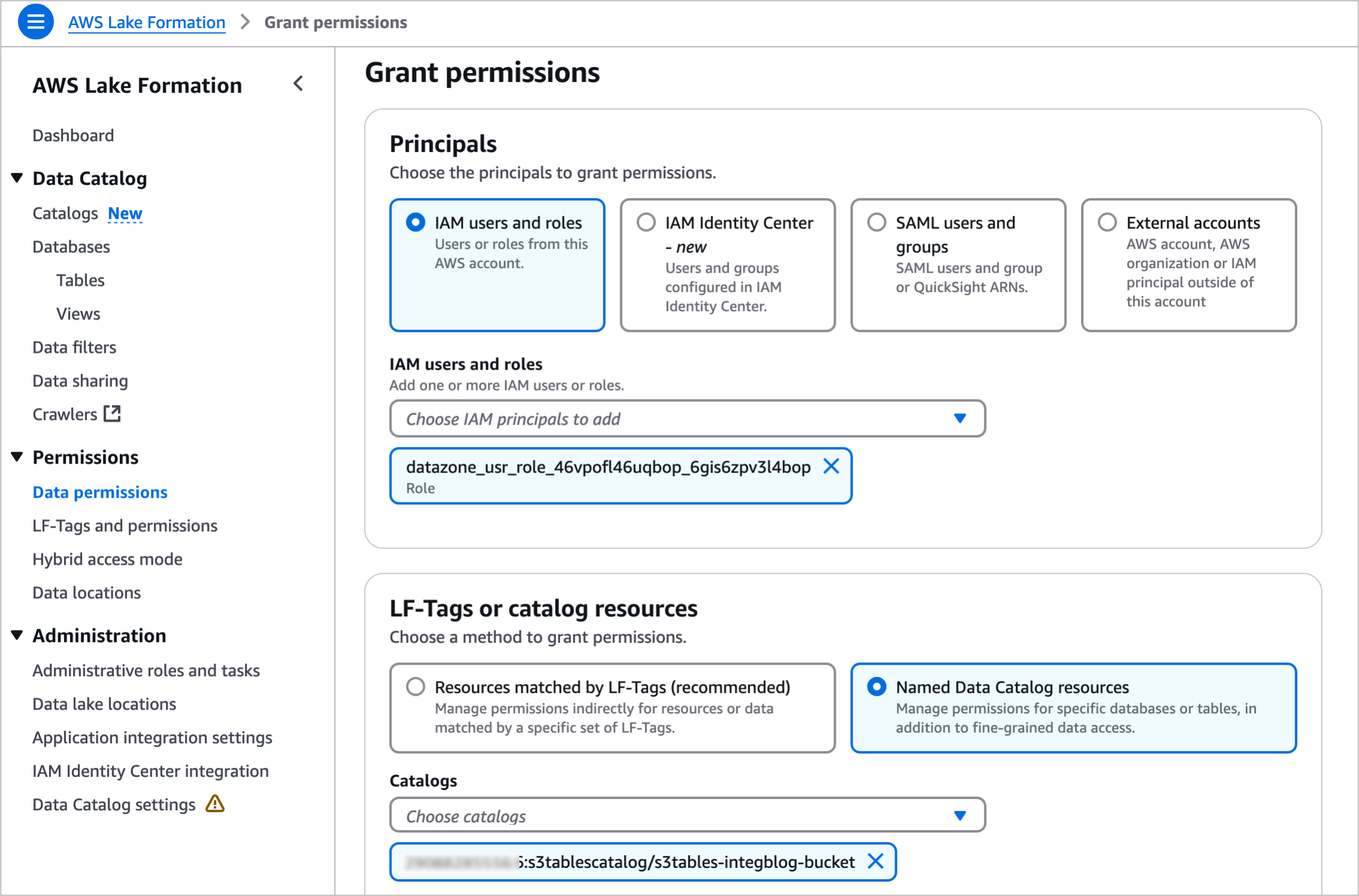
Go to the AWS Lake Formation console and grant permissions for AWS Identity and Access Management (IAM) users and roles. In the in the Principals section, select the <project role ARN> noted in the previous paragraph. Choose Named Data Catalog resources in the LF-Tags or catalog resources section and select the table bucket name you created for Catalogs. To learn more, visit Overview of Lake Formation permissions in the AWS documentation.
When you return to SageMaker Unified Studio, you can see your table bucket project under Lakehouse in the Data menu in the left navigation pane of project page. When you choose Actions, you can select how to query your table bucket data in Amazon Athena, Amazon Redshift, or JupyterLab Notebook.
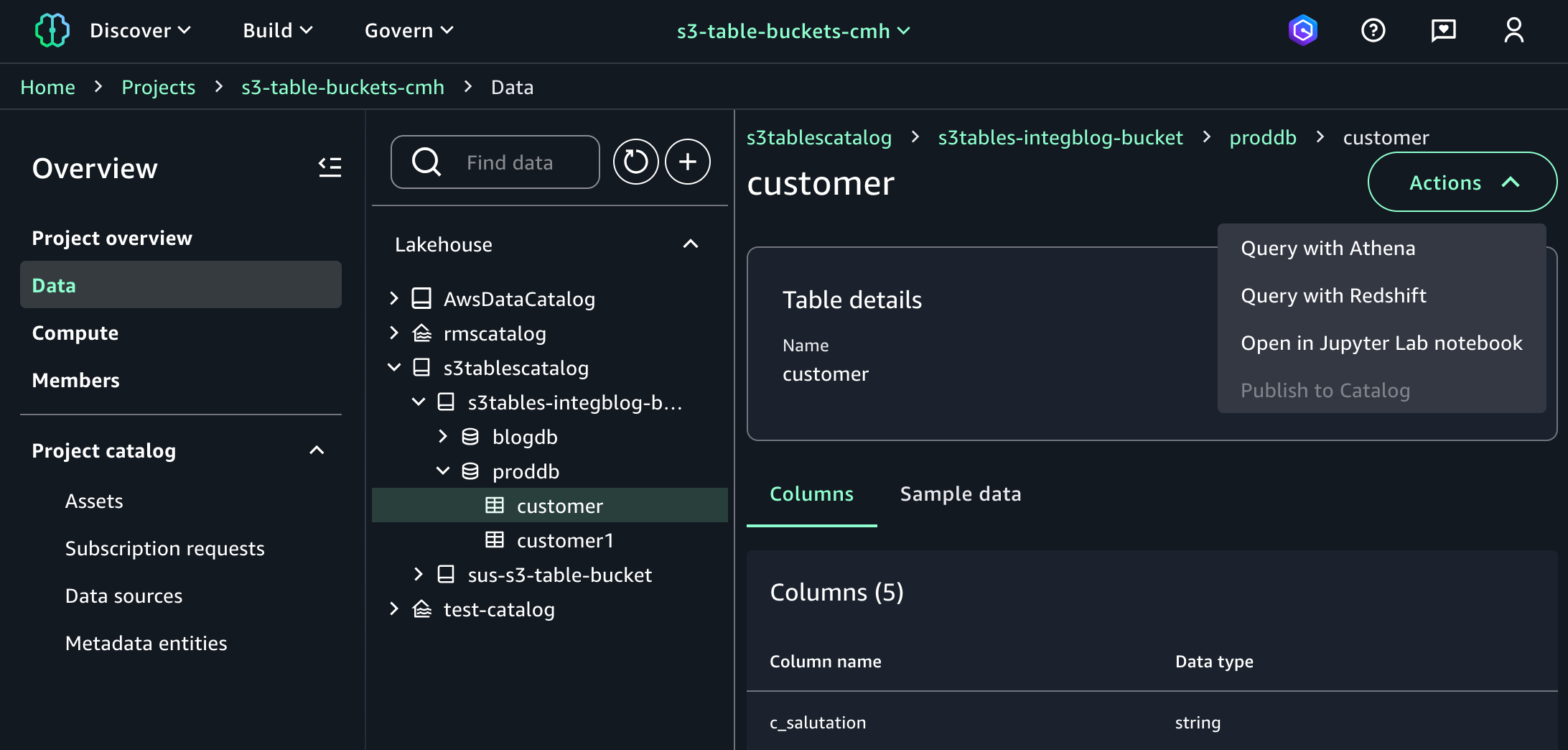
When you choose Query with Athena, it automatically goes to Query Editor to run data query language (DQL) and data manipulation language (DML) queries on S3 tables using Athena.
Here is a sample query using Athena:
select * from "s3tablecatalog/s3tables-integblog-bucket”.”proddb"."customer" limit 10;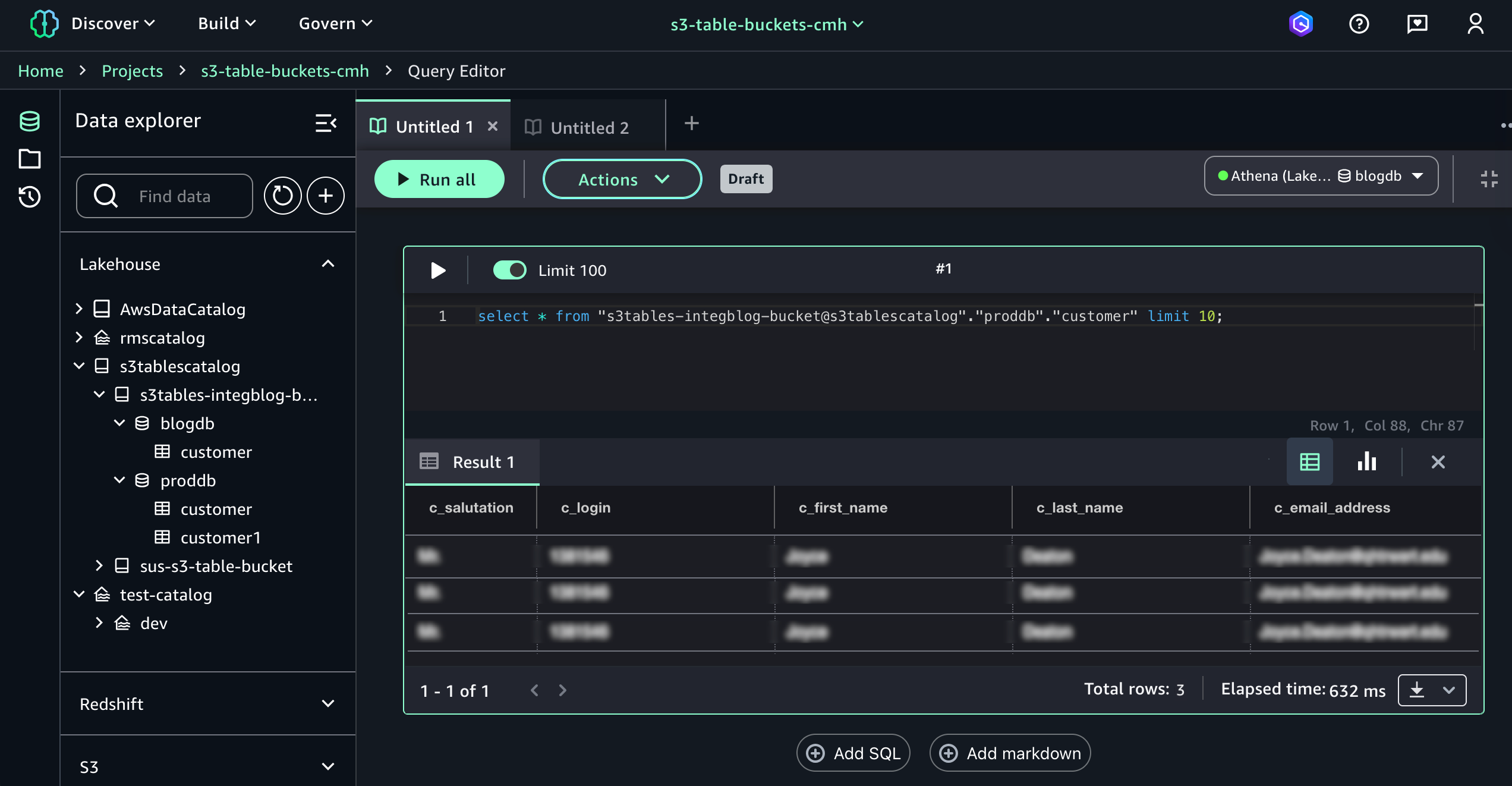
To query with Amazon Redshift, you should set up Amazon Redshift Serverless compute resources for data query analysis. And then you choose Query with Redshift and run SQL in the Query Editor. If you want to use JupyterLab Notebook, you should create a new JupyterLab space in Amazon EMR Serverless.
3. Join data from other sources with S3 Tables data
With S3 Tables data now available in SageMaker Lakehouse, you can join it with data from data warehouses, online transaction processing (OLTP) sources like relational or non-relational database, Iceberg tables, and other third party sources to gain more comprehensive and deeper insights.
For example, you can add connections to data sources such as Amazon DocumentDB, Amazon DynamoDB, Amazon Redshift, PostgreSQL, MySQL, Google BigQuery, or Snowflake and combine data using SQL without extract, transform, and load (ETL) scripts.
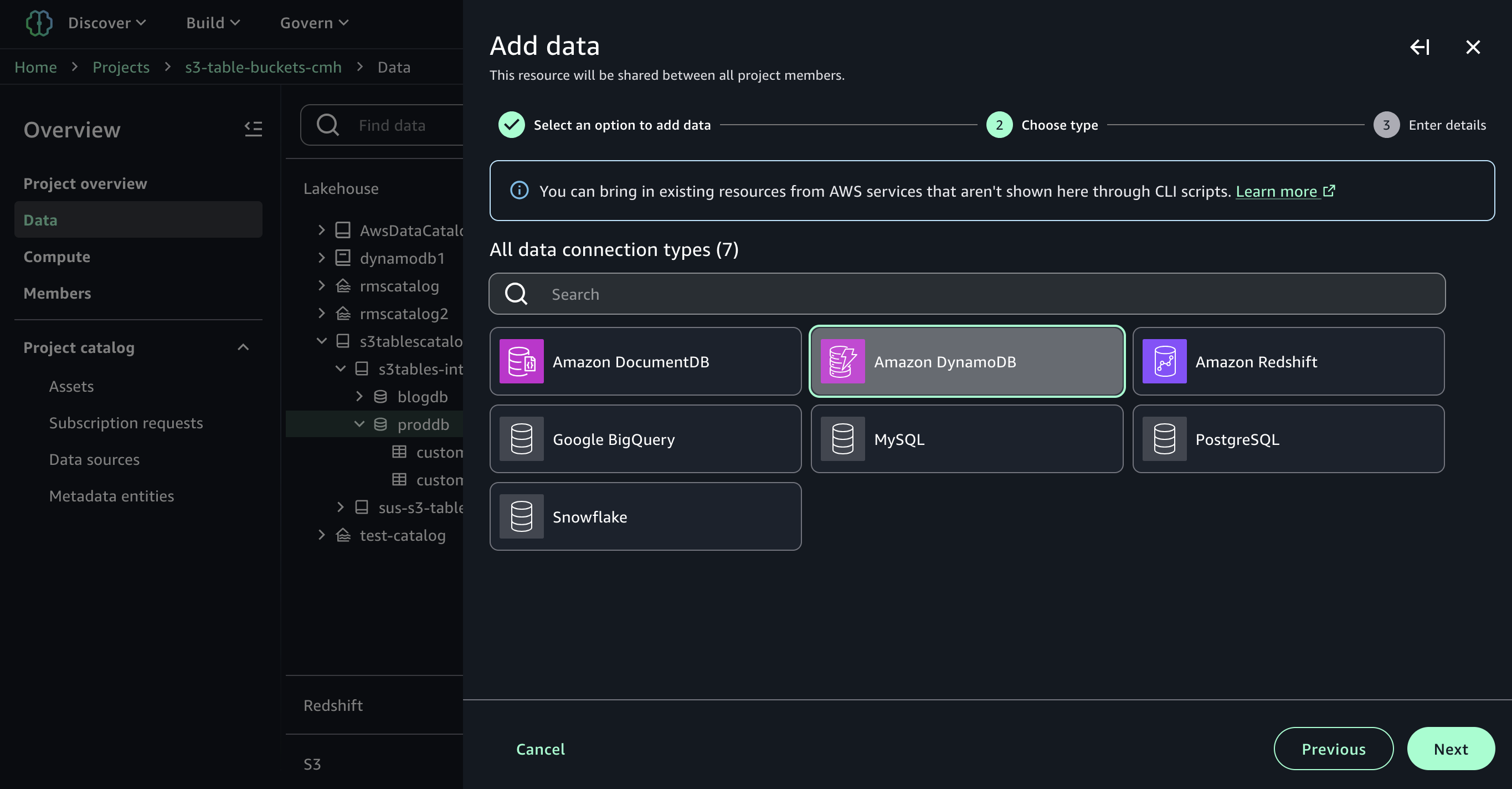
Now you can run the SQL query in the Query editor to join the data in the S3 Tables with the data in the DynamoDB.
Here is a sample query to join between Athena and DynamoDB:
select * from "s3tablescatalog/s3tables-integblog-bucket"."blogdb"."customer",
"dynamodb1"."default"."customer_ddb" where cust_id=pid limit 10;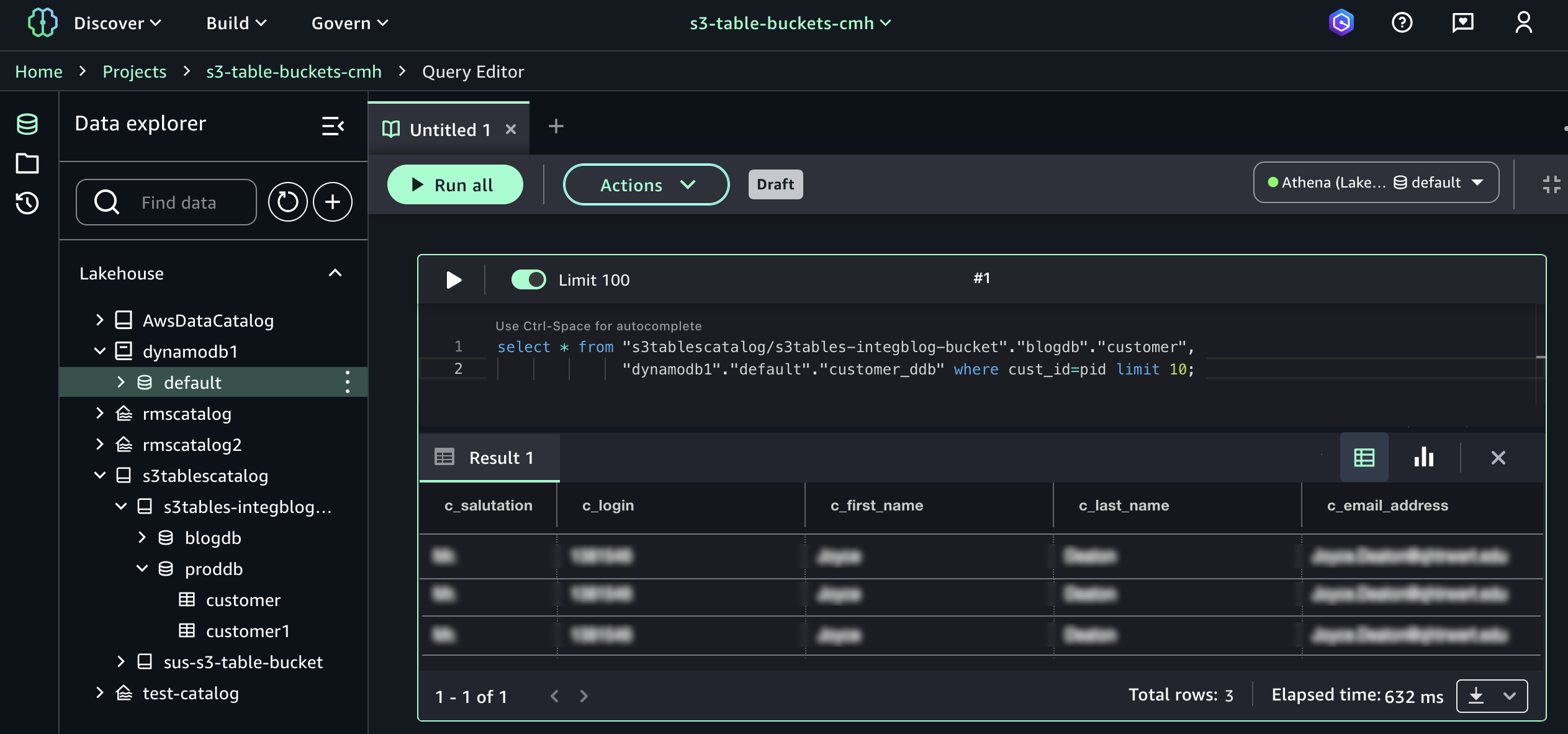
To learn more about this integration, visit Amazon S3 Tables integration with Amazon SageMaker Lakehouse in the AWS documentation.
Now available
S3 Tables integration with SageMaker Lakehouse is now generally available in all AWS Regions where S3 Tables are available. To learn more, visit the S3 Tables product page and the SageMaker Lakehouse page.
Give S3 Tables a try in the SageMaker Unified Studio today and send feedback to AWS re:Post for Amazon S3 and AWS re:Post for Amazon SageMaker or through your usual AWS Support contacts.
In the annual celebration of the launch of Amazon S3, we will introduce more awesome launches for Amazon S3 and Amazon SageMaker. To learn more, join the AWS Pi Day event on March 14.
— Channy
—
How is the News Blog doing? Take this 1 minute survey!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)