Today, we are thrilled to announce the general availability of a fully managed MLflow capability on Amazon SageMaker. MLflow, a widely-used open-source tool, plays a crucial role in helping machine learning (ML) teams manage the entire ML lifecycle. With this new launch, customers can now effortlessly set up and manage MLflow Tracking Servers with just a few steps, streamlining the process and boosting productivity.
Data Scientists and ML developers can leverage MLflow to track multiple attempts at training models as runs within experiments, compare these runs with visualizations, evaluate models, and register the best models to a Model Registry. Amazon SageMaker eliminates the undifferentiated heavy lifting required to set up and manage MLflow, providing ML administrators with a quick and efficient way to establish secure and scalable MLflow environments on AWS.
Core components of managed MLflow on SageMaker
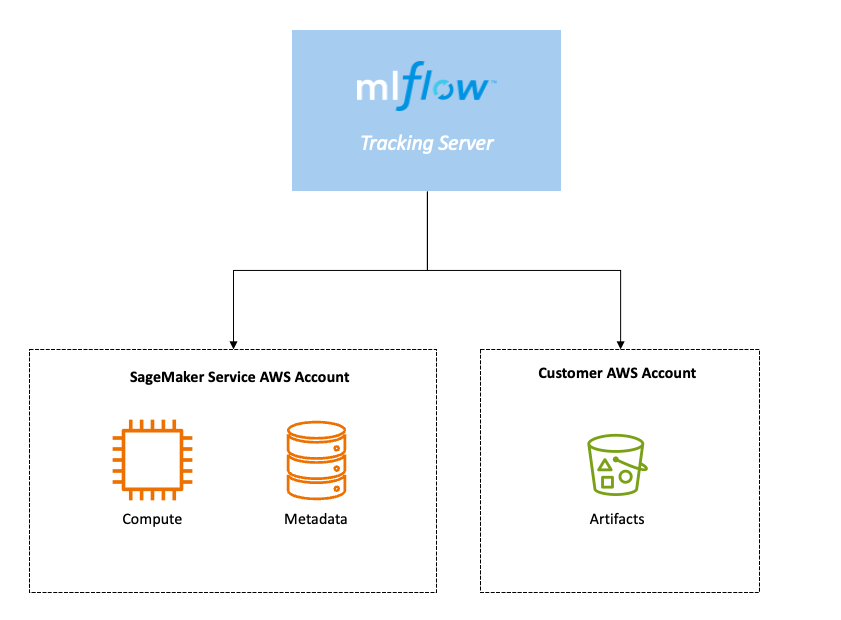
The fully managed MLflow capability on SageMaker is built around three core components:
- MLflow Tracking Server – With just a few steps, you can create an MLflow Tracking Server through the SageMaker Studio UI. This stand-alone HTTP server serves multiple REST API endpoints for tracking runs and experiments, enabling you to begin monitoring your ML experiments efficiently. For more granular security customization, you can also use the AWS Command Line Interface (AWS CLI).
- MLflow backend metadata store – The metadata store is a critical part of the MLflow Tracking Server, where all metadata related to experiments, runs, and artifacts is persisted. This includes experiment names, run IDs, parameter values, metrics, tags, and artifact locations, ensuring comprehensive tracking and management of your ML experiments.
- MLflow artifact store – This component provides a storage location for all artifacts generated during ML experiments, such as trained models, datasets, logs, and plots. Utilizing an Amazon Simple Storage Service (Amazon S3) bucket, it offers a customer-managed AWS account for storing these artifacts securely and efficiently.
Benefits of Amazon SageMaker with MLflow
Using Amazon SageMaker with MLflow can streamline and enhance your machine learning workflows:
- Comprehensive Experiment Tracking: Track experiments in MLflow across local integrated development environments (IDEs), managed IDEs in SageMaker Studio, SageMaker training jobs, SageMaker processing jobs, and SageMaker Pipelines.
- Full MLflow Capabilities: Use all MLflow experimentation capabilities such as MLflow Tracking, MLflow Evaluations, and MLflow Model Registry, are available to easily compare and evaluate the results of training iterations.
- Unified Model Governance: Models registered in MLflow automatically appear in the SageMaker Model Registry, offering a unified model governance experience that helps you deploy MLflow models to SageMaker inference without building custom containers.
- Efficient Server Management: Provision, remove, and upgrade MLflow Tracking Servers as desired using SageMaker APIs or the SageMaker Studio UI. SageMaker manages the scaling, patching, and ongoing maintenance of your tracking servers, without customers needing to manage the underlying infrastructure.
- Enhanced Security: Secure access to MLflow Tracking Servers using AWS Identity and Access Management (IAM). Write IAM policies to grant or deny access to specific MLflow APIs, ensuring robust security for your ML environments.
- Effective Monitoring and Governance: Monitor the activity on an MLflow Tracking Server using Amazon EventBridge and AWS CloudTrail to support effective governance of their Tracking Servers.
MLflow Tracking Server prerequisites (environment setup)
- Create a SageMaker Studio domain
You can create a SageMaker Studio domain using the new SageMaker Studio experience.
- Configure the IAM execution role
The MLflow Tracking Server needs an IAM execution role to read and write artifacts to Amazon S3 and register models in SageMaker. You can use the Studio domain execution role as the Tracking Server execution role or you can create a separate role for the Tracking Server execution role. If you choose to create a new role for this, refer to the SageMaker Developer Guide for more details on the IAM role. If you choose to update the Studio domain execution role, refer to the SageMaker Developer Guide for details on what IAM policy the role needs.
Create the MLflow Tracking Server
In the walkthrough, I use the default settings for creating an MLflow Tracking Server, which include the Tracking Server version (2.13.2), the Tracking Server size (Small), and the Tracking Server execution role (Studio domain execution role). The Tracking Server size determines how much usage a Tracking Server will support, and we recommend using a Small Tracking Server for teams of up to 25 users. For more details on Tracking Server configurations, read the SageMaker Developer Guide.
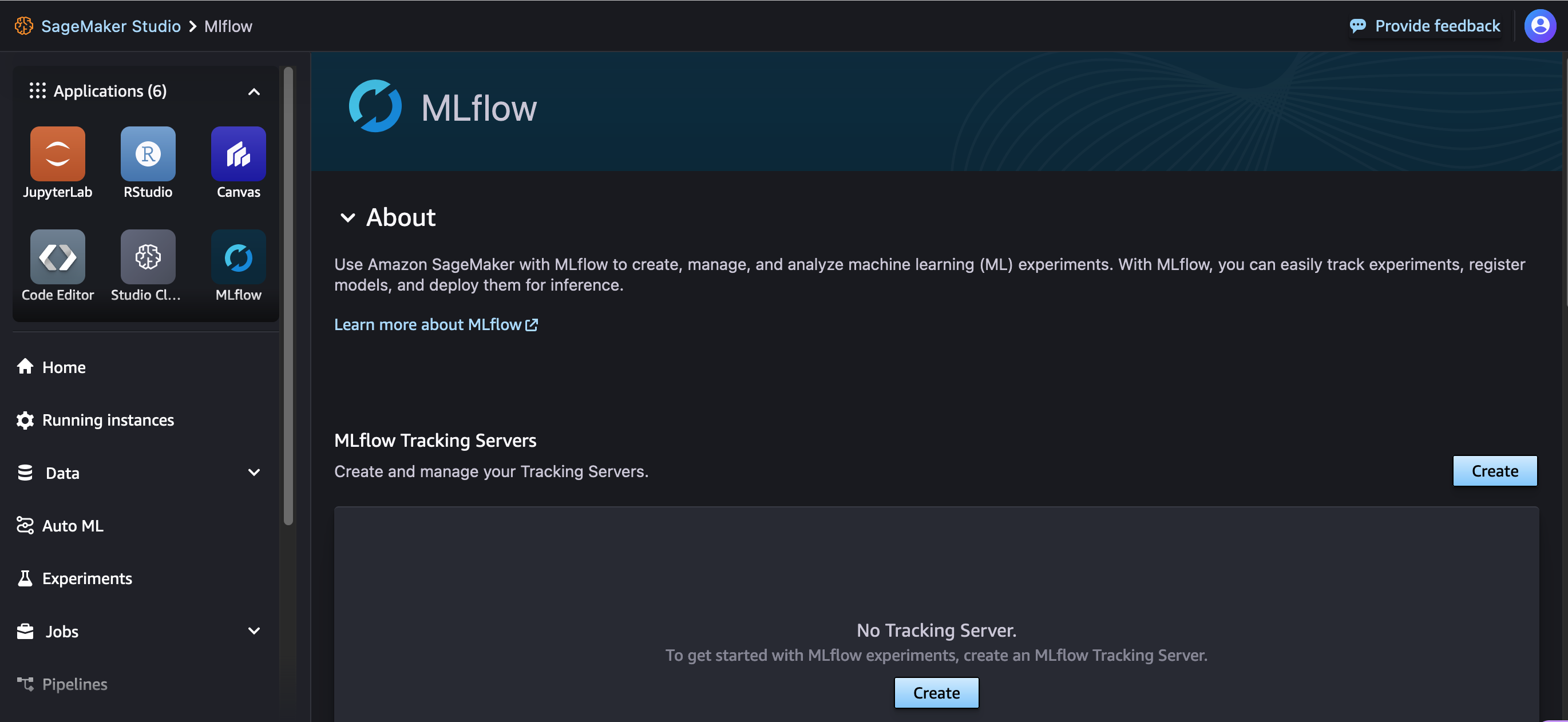
To get started, in your SageMaker Studio domain created during your environment set up detailed earlier, select MLflow under Applications and choose Create.
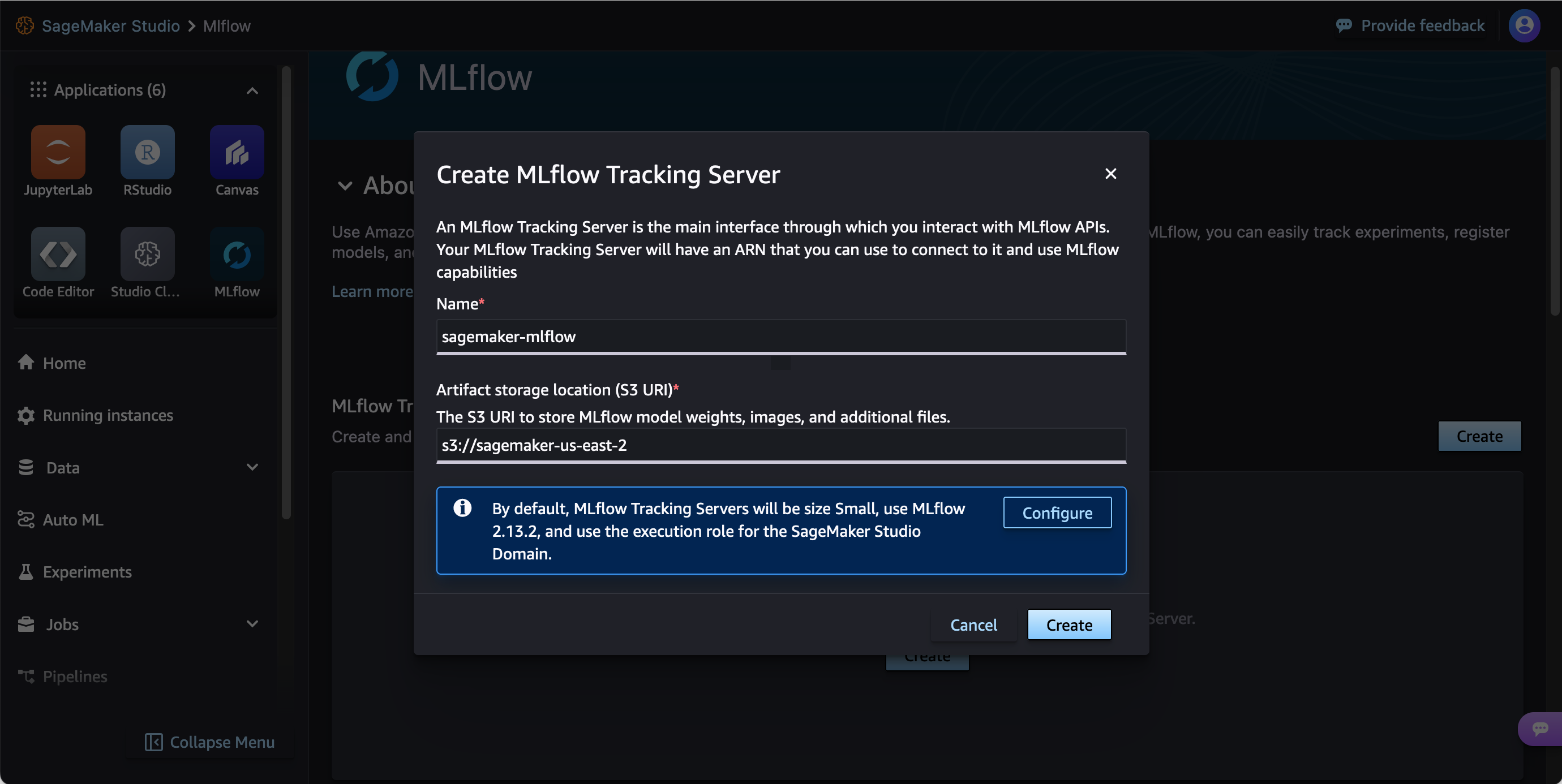
Next, provide a Name and Artifact storage location (S3 URI) for the Tracking Server.
Creating an MLflow Tracking Server can take up to 25 minutes.
Track and compare training runs
To get started with logging metrics, parameters, and artifacts to MLflow, you need a Jupyter Notebook and your Tracking Server ARN that was assigned during the creation step. You can use the MLflow SDK to keep track of training runs and compare them using the MLflow UI.
To register models from MLflow Model Registry to SageMaker Model Registry, you need the sagemaker-mlflow plugin to authenticate all MLflow API requests made by the MLflow SDK using AWS Signature V4.
- Install the MLflow SDK and
sagemaker-mlflowplugin
In your notebook, first install the MLflow SDK and sagemaker-mlflow Python plugin.pip install mlflow==2.13.2 sagemaker-mlflow==0.1.0 - Track a run in an experiment
To track a run in an experiment, copy the following code into your Jupyter notebook.import mlflow import mlflow.sklearn from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # Replace this with the ARN of the Tracking Server you just created arn = 'YOUR-TRACKING-SERVER-ARN' mlflow.set_tracking_uri(arn) # Load the Iris dataset iris = load_iris() X, y = iris.data, iris.target # Split the data into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train a Random Forest classifier rf_model = RandomForestClassifier(n_estimators=100, random_state=42) rf_model.fit(X_train, y_train) # Make predictions on the test set y_pred = rf_model.predict(X_test) # Calculate evaluation metrics accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred, average='weighted') recall = recall_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted') # Start an MLflow run with mlflow.start_run(): # Log the model mlflow.sklearn.log_model(rf_model, "random_forest_model") # Log the evaluation metrics mlflow.log_metric("accuracy", accuracy) mlflow.log_metric("precision", precision) mlflow.log_metric("recall", recall) mlflow.log_metric("f1_score", f1) - View your run in the MLflow UI
Once you run the notebook shown in Step 2, you will see a new run in the MLflow UI.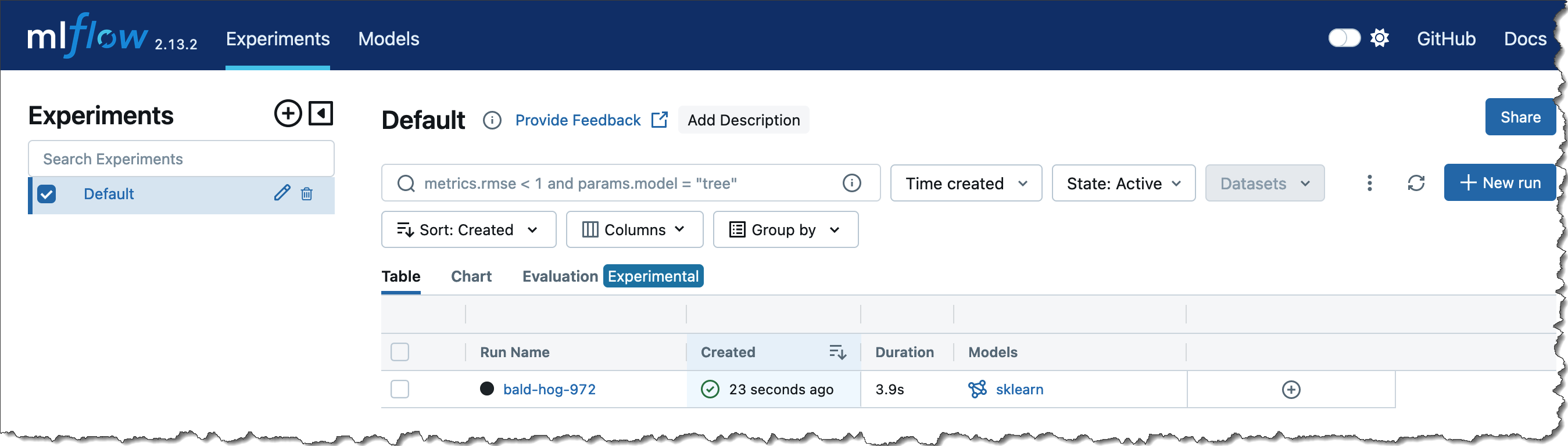
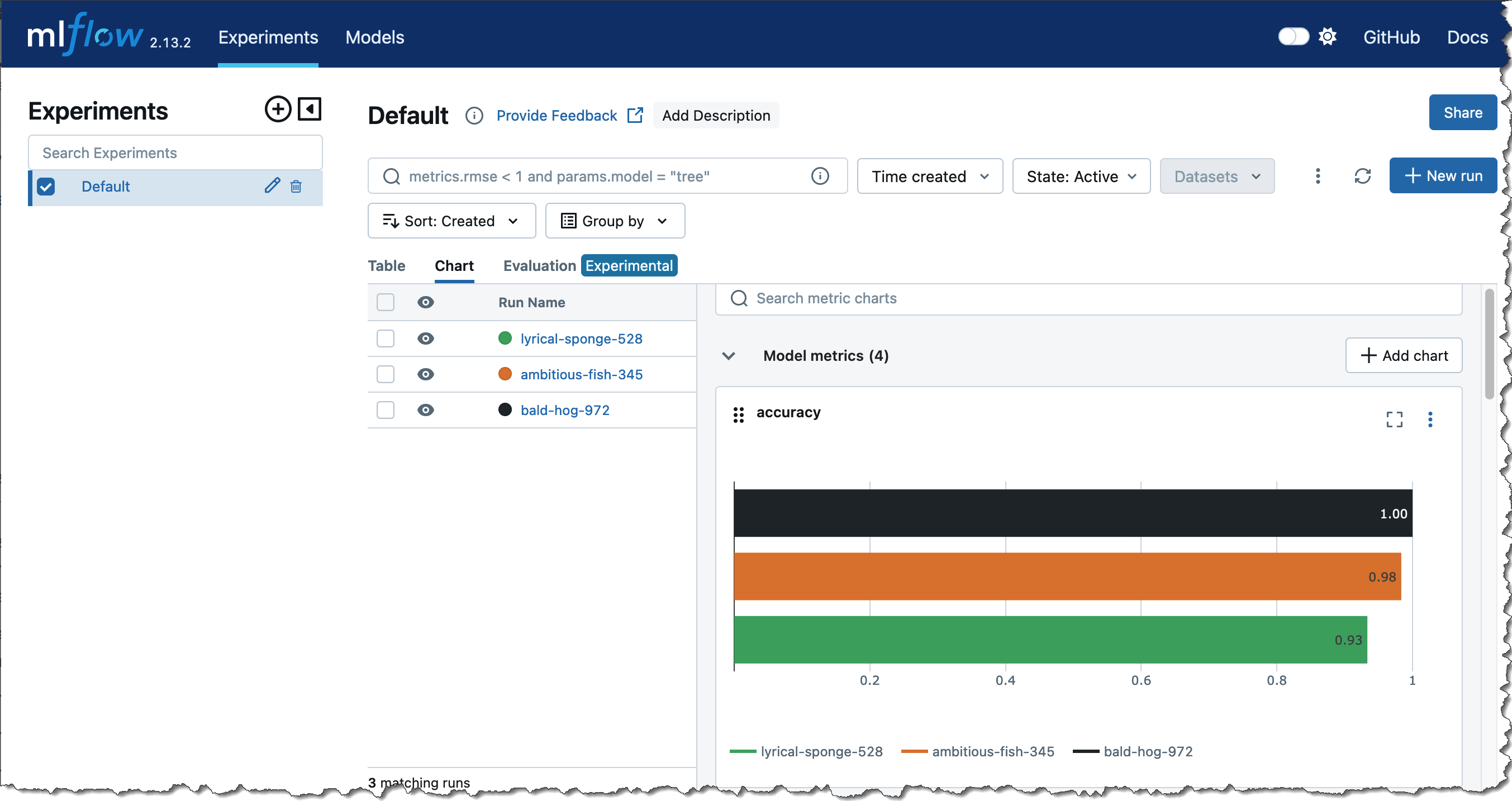
- Compare runs
You can run this notebook multiple times by changing therandom_stateto generate different metric values for each training run.
Register candidate models
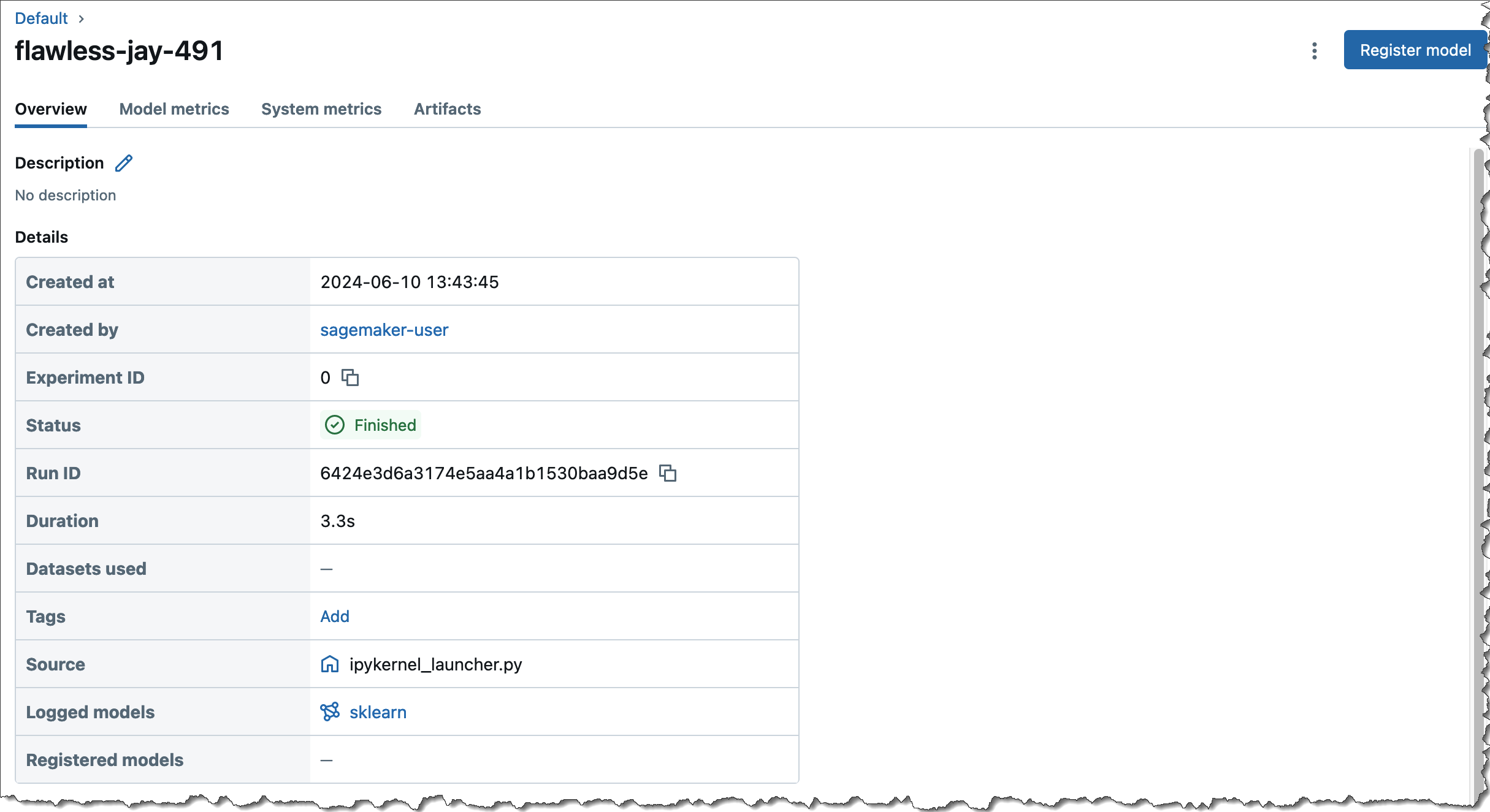
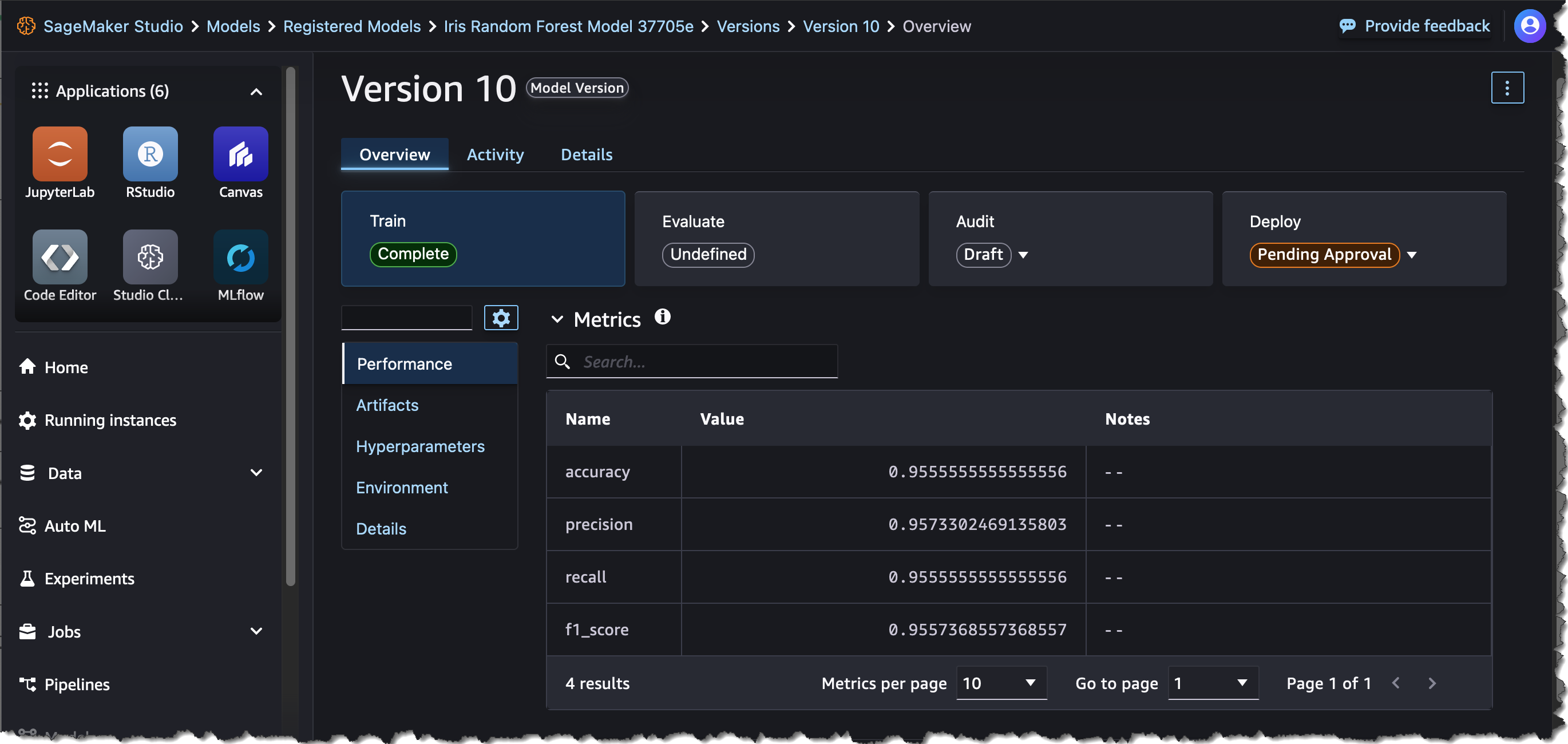
Once you’ve compared the multiple runs as detailed in Step 4, you can register the model whose metrics best meet your requirements in the MLflow Model Registry. Registering a model indicates potential suitability for production deployment and there will be further testing to validate this suitability. Once a model is registered in MLflow it automatically appears in the SageMaker Model Registry for a unified model governance experience so you can deploy MLflow models to SageMaker inference. This enables data scientists who primarily use MLflow for experimentation to hand off their models to ML engineers who govern and manage production deployments of models using the SageMaker Model Registry.
Here is the model registered in the MLflow Model Registry.
Here is the model registered in the SageMaker Model Registry.
Clean up
Once created, an MLflow Tracking Server will incur costs until you delete or stop it. Billing for Tracking Servers is based on the duration the servers have been running, the size selected, and the amount of data logged to the Tracking Servers. You can stop Tracking Servers when they are not in use to save costs or delete them using API or the SageMaker Studio UI. For more details on pricing, see the Amazon SageMaker pricing.
Now available
SageMaker with MLflow is generally available in all AWS Regions where SageMaker Studio is available, except China and US GovCloud Regions. We invite you to explore this new capability and experience the enhanced efficiency and control it brings to your machine learning projects. To learn more, visit the SageMaker with MLflow product detail page.
For more information, visit the SageMaker Developer Guide and send feedback to AWS re:Post for SageMaker or through your usual AWS support contacts.
— Veliswa