PostgreSQL with the pgvector extension allows tables to be used as storage for vectors, each of which is saved as a row. It also allows any number of metadata columns to be added. In an enterprise application, this hybrid capability of storing both vectors and tabular data provides developers with a flexibility that is not available in pure vector databases.
While pure vector databases can be tuned for extreme high performance, pgvector may not be. However, for medium-sized retrieval-augmented generation (RAG) applications (involving around 100K documents, typically) the performance of pgvector is more than adequate. If you are building a knowledge management application for a group or small department, such an architecture is a simple way to get started. (For even smaller, single-user applications, you could use SQLite with the sqlite-vss extension.)
As many developers have come to realize, “Just use Postgres” is generally a good strategy. If and when your needs grow, you might want to swap in a larger and more performant vector database. Until then, Postgres will do the job and allow us to build our application quickly.
Reviewing retrieval-augmented generation
Before you dive in, you might find it helpful to review my two previous articles on building RAG applications:
- Retrieval-augmented generation, step by step
- Fully local retrieval-augmented generation, step by step
In the first article, we built a simple “hello world” RAG application using Python, LangChain, and an OpenAI chat model. We used the OpenAI embeddings API to generate embeddings, saved those embeddings in a local vector store (FAISS), then asked the OpenAI chat model two questions about a single retrieved document, President Biden’s February 7, 2023, State of the Union Address.
To refresh our memory about the workflow in RAG, the steps were as follows:
- We chunked the text document and submitted an array of chunks to OpenAI’s embeddings API.
- We got back a set of vectors with floating point encodings of the chunks — one vector of floats per chunk. These are the embeddings for the document.
- We used Faiss to store these encoded chunks or embeddings and do similarity searches on them.
- We created a query and used it to do a similarity search of the embeddings store, getting back those chunks that potentially contain useful context for answering our query.
- We submitted the combination of query and context to OpenAI via its chat interface.
- We got a response from OpenAI that answered our question in the context of the relevant information in our chunks.
In the second article, we did an equivalent exercise but instead ran everything locally so that no information left the premises. This was our first step toward pragmatic and relevant use of RAG in the enterprise. We replaced OpenAI’s embeddings API with a locally run embeddings generator from a library called Sentence Transformers. We used SQLite with the sqlite-vss extension as our local vector database. And we used Ollama to run the Llama 2 large language model locally.
Now we will take a deeper look at the vector database, which so far has been a mysterious black box. By using Postgres as a base for vector storage we can use familiar tools to look inside and inspect what exactly is stored inside a vector database. By using the familiar workhorse, Postgres, we’ll try to take some of the mystery out of vector databases.
RAG with Postgres in two parts
In this exploration we will do our coding in two parts. First, we will ingest the text of multiple Wikipedia entries into a single vector database. Second, we will use Postgres and SQL to do a similarity search on that text, then use the results to query a local large language model run by Ollama.
To create a knowledge base, we will need ways to import multiple kinds of documents into the vector database. For this we can use loaders and parsers from libraries such as LangChain or LlamaIndex. For particularly large or complex PDF documents, we may need libraries specialized for PDF. Several such libraries are available in Java and Python. Note that, for PDFs with embedded images or tables, you may need to draw on a combination of techniques, especially OCR via Tesseract, to extract the data hidden in those images and tables.
Let’s take a close look at our two parts. The code is documented in detail, so we will first outline the steps in each part and then present the code.
Part 1. Create a vector database in Postgres
In part 1 we create a vector database in Postgres and populate it with data from a vectorized set of HTML pages. The steps:
- We install the Postgres extension called pgvector, which enables tables to have columns of type vector where vector is a set of floats. In this example we use a 768-dimensional vector, i.e. a vector of length 768.
- We create a table that will save the articles for our knowledge base — the text of each article, the title of the article, and a vector embedding of the article text. We name the table
articlesand the columnstitle,text, andembedding. - We extract the content at four Wikipedia URLs and separate the title and content for each.
- We clean each article body, divide the text into chunks of 500 characters, and use an embedding model to create a 768-dimensional vector from each chunk. The vector is a numerical representation (a float) of the meaning of the chunk of text.
- We save the title, a chunk from the body, and the embedding vector for the chunk in a row of the database. For each article, there are as many vectors as there are chunks.
- We index the vector column for similarity search in Part 2.
import psycopg2
from sentence_transformers import SentenceTransformer
import requests
from bs4 import BeautifulSoup
import re
import ollama
# Your connection params here
MY_DB_HOST = 'localhost'
MY_DB_PORT = 5432
MY_DB_NAME = 'nitin'
MY_DB_USER = 'nitin'
MY_DB_PASSWORD = ''
# Set up the database connection
conn = psycopg2.connect(
host=MY_DB_HOST,
port=MY_DB_PORT,
dbname=MY_DB_NAME,
user=MY_DB_USER,
password=MY_DB_PASSWORD
)
cur = conn.cursor()
# Create the articles table with the pgvector extension
# If the pgvector extension is not installed on your machine it will need to be installed.
# See https://github.com/pgvector/pgvector or cloud instances with pgvector installed.
# First create the pgvector extension, then a table with a 768 dim vector column for embeddings.
# Note that the title and full text of the article is also saved with the embedding.
# This allows vector similarity search on the embedding column, returning matched text
# along with matched embeddings depending on what is needed.
# After this SQL command is executed we will have
# a) a pgvector extension installed if it did not already exist
# b) an empty table with a column of type vector along with two columns,
# one to save the title of the article and one to save a chunk of text.
# Postgres does not put a limit on the number of dimensions in pgvector embeddings.
# It is worth experimenting with larger lengths but note they need to match the length of embeddings
# created by the model you use. Embeddings of ~1k, 2k, or more dimensions are common among embeddings APIs.
cur.execute('''
CREATE EXTENSION IF NOT EXISTS vector;
DROP TABLE IF EXISTS articles;
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title TEXT,
text TEXT,
embedding VECTOR(768)
);
''')
conn.commit()
# Below are the sources of content for creating embeddings to be inserted in our demo vector db.
# Feel free to add your own links but note that different sources other than Wikipedia may
# have different junk characters and may require different pre-processing.
# As a start try other Wikipedia pages, then expand to other sources.
urls= [
'https://en.wikipedia.org/wiki/Pentax_K-x',
'https://en.wikipedia.org/wiki/2008_Tour_de_France',
'https://en.wikipedia.org/wiki/Onalaska,_Texas',
'https://en.wikipedia.org/wiki/List_of_extinct_dog_breeds'
]
# Fetch the HTML at a given link and extract only the text, separating title and content.
# We will use this text to extract content from Wikipedia articles to answer queries.
def extract_title_and_content(url):
try:
response = requests.get(url)
if response.status_code == 200: # success
# Create a BeautifulSoup object to parse the HTML content
soup = BeautifulSoup(response.content, 'html.parser')
# Extract the title of the page
title = soup.title.string.strip() if soup.title else ""
# Extract the text content from the page
content = soup.get_text(separator=' ')
return {"title": title, "text": content}
else:
print(f"Failed to retrieve content from {url}. Status code: {response.status_code}")
return None
except requests.exceptions.RequestException as e:
print(f"Error occurred while retrieving content from {url}: {str(e)}")
return None
# Create the embedding model
# This is the model we use to generate embeddings, i.e. to encode text chunks into numeric vectors of floats.
# Sentence Transformers (sbert.net) is a collection of transformer models designed for creating embeddings
# from sentences. These are trained on data sets used for different applications. We use one tuned for Q&A,
# hence the 'qa' in the name. There are other embedding models, some tuned for speed, some for breadth, etc.
# The site sbert.net is worth studying for picking the right model for other uses. It's also worth looking
# at the embedding models of providers like OpenAI, Cohere, etc. to learn the differences, but note that
# the use of an online model involves a potential loss of privacy.
embedding_model = SentenceTransformer('multi-qa-mpnet-base-dot-v1')
articles = []
embeddings = []
# Extract title,content from each URL and store it in the list.
for url in urls:
article = extract_title_and_content(url)
if article:
articles.append(article)
for article in articles:
raw_text = article["text"]
# Pre-processing: Replace large chunks of white space with a space, eliminate junk characters.
# This will vary with each source and will need custom cleanup.
text = re.sub(r's+', ' ', raw_text)
text = text.replace("]", "").replace("[", "")
# chunk into 500 character chunks, this is a typical size, could be lower if total size of article is small.
chunks = [text[i:i + 500] for i in range(0, len(text), 500)]
for chunk in chunks:
# This is where we invoke our model to generate a list of floats.
# The embedding model returns a numpy ndarray of floats.
# Psycopg coerces the list into a vector for insertion.
embedding = embedding_model.encode([chunk])[0].tolist()
cur.execute('''
INSERT INTO articles (title, text, embedding)
VALUES (%s, %s, %s); ''', (article["title"], chunk, embedding)
)
embeddings.append(embedding)
conn.commit()
# Create an index
# pgvector allows different indexes for similarity search.
# See the docs in the README at https://github.com/pgvector/pgvector for detailed explanations.
# Here we use 'hnsw' which is an index that assumes a Hierarchical Network Small Worlds model.
# HNSW is a pattern seen in network models of language. Hence this is one of the indexes
# that is expected to work well for language embeddings. For this small demo it will probably not
# make much of a difference which index you use, and the others are also worth trying.
# The parameters provided in the 'USING' clause are 'embedding vector_cosine_ops'
# The first, 'embedding' in this case, needs to match the name of the column which holds embeddings.
# The second, 'vector_cosine_ops', is the operation used for similarity search i.e. cosine similarity.
# The same README doc on GitHub gives other choices but for most common uses it makes little difference
# hence cosine similarity is used as our default.
cur.execute('''
CREATE INDEX ON articles USING hnsw (embedding vector_cosine_ops);
''')
conn.commit()
cur.close()
conn.close()
# End of file
Part 2. Retrieve context from the vector database and query the LLM
In part 2 we ask a natural language question of our knowledge base, using similarity search to find a context and using an LLM (in this case Meta’s Llama 3) to generate an answer to the question in the provided context. The steps:
- We encode our natural language query as a vector using the same embedding model we used to encode the chunks of text we extracted from the Wikipedia pages.
- We perform a similarity search on this vector using a SQL query. Similarity, or specifically cosine similarity, is a way to find the vectors in our database that are nearest to the vector query. Once we find the nearest vectors, we can use them to retrieve the corresponding text that is saved with each vector. That’s the context for our query to the LLM.
- We append this context to our natural language query text, explicitly telling the LLM that the provided text is to be taken as the context for answering the query.
- We use a programmatic wrapper around Ollama to pass the natural language query and contextual text to the LLM’s request API and fetch the response. We submit three queries, and we receive the answer in context for each query. An example screenshot for the first query is shown below.
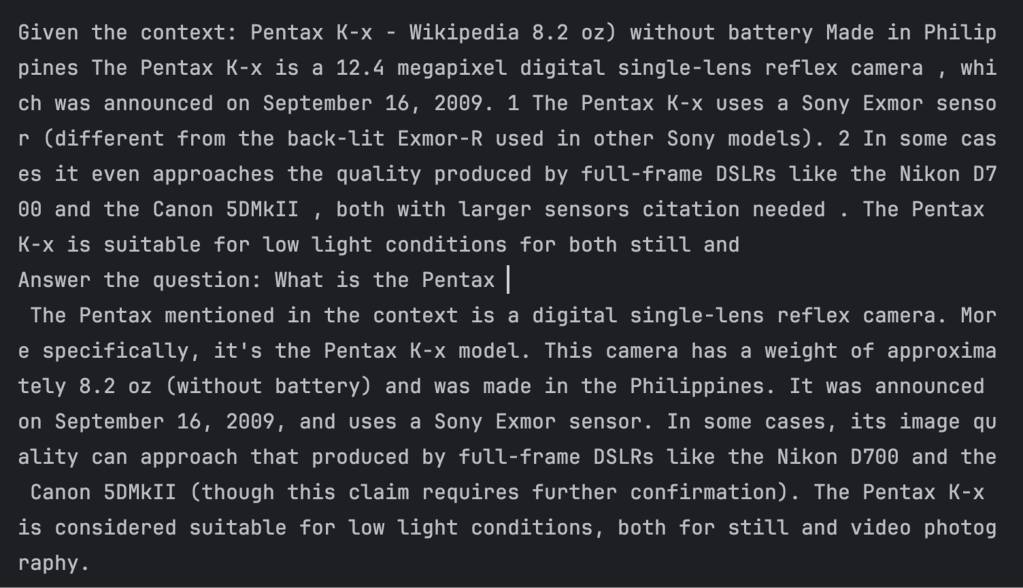
IDG
import psycopg2
import ollama
import re
from sentence_transformers import SentenceTransformer
# Your connection params and credentials here
MY_DB_HOST = 'localhost'
MY_DB_PORT = 5432
MY_DB_NAME = 'nitin'
MY_DB_USER = 'nitin'
MY_DB_PASSWORD = ''
# Note that this model needs to be the same as the model used to create the embeddings in the articles table.
embedding_model = SentenceTransformer('multi-qa-mpnet-base-dot-v1')
# Below are some low-level functions to clean up the text returned from our Wikipedia URLs.
# It may be necessary to develop small custom functions like these to handle the vagaries of each of your sources.
# At this time there is no 'one size fits all' tool that does the cleanup in a single call for all sources.
# The 'special_print' function is a utility for printing chunked text on the console.
def chunk_string(s, chunk_size):
chunks = [s[i:i+chunk_size] for i in range(0, len(s),chunk_size)]
return 'n'.join(chunks)
def clean_text(text):
text = re.sub(r's+', ' ', text)
return text.replace("[", "").replace("]", "")
def special_print(text, width=80):
print(chunk_string(clean_text(text), width))
return
def query_ollama(query, context):
# Note: The model can be changed to suit your available resources.
# Models smaller than 8b may have less satisfactory performance.
response = ollama.chat(model='llama3:8b', messages=[
{
'role': 'user',
'content': context + query,
},
])
response_content = response['message']['content']
special_print(context + "n")
special_print(query + "n")
special_print(response_content + "n")
return response_content
# Create sample queries
# Set up the database connection
conn = psycopg2.connect(
host=MY_DB_HOST,
port=MY_DB_PORT,
dbname=MY_DB_NAME,
user=MY_DB_USER,
password=MY_DB_PASSWORD
)
cur = conn.cursor()
# There are 3 queries each focused on one of the 4 pages we ingested.
# One is deliberately left out to make sure that the extra page does not create hallucinations.
# Feel free to add or remove queries.
queries = [
"What is the Pentax",
"In what state in the USA is Onalaska",
"Is the Doberman Pinscher extinct?"
]
# Perform similarity search for each query
for query in queries:
# Here we do the crucial step of encoding a query using the same embedding model
# as used in populating the vector db.
query_embedding = embedding_model.encode([query])[0].tolist()
# Here we fetch the title and article text for the top match using cosine similarity search.
# We pass in the embedding of the query text to be matched.
# The query embedding will be matched by similarity search to the closest embedding in our vector db.
# the operator is the cosine similarity search.
# We are asking for the top three matches ordered by similarity.
# We will pick the top one; we could just as easily have asked for the top one via 'LIMIT 1'.
cur.execute('''
SELECT title, text
FROM articles
ORDER BY embedding CAST(%s as vector)
LIMIT 3;
''', (query_embedding,))
result = cur.fetchone()
if result:
article_title = result[0]
relevant_text = result[1]
#special_print(f"Query: {query}")
#special_print(f"Relevant text: {relevant_text}")
#special_print(f"Article title: {article_title}")
print("------------------------------------------n")
# Format the query to the LLM giving explicit instructions to use our search result as context.
query_ollama("Answer the question: " + query + "n", "Given the context: " + "n" + article_title + "n" + relevant_text + "n")
else:
print(f"Query: {query}")
print("No relevant text found.")
print("---")
# Close the database connection
cur.close()
conn.close()
# End of file
Note that this is the same approach we took in the earlier articles except we are using Postgres with a vector extension. This allows us to rely on familiar SQL concepts but with a single extra operator () and to extend our RDBMS knowledge to encompass vector data via the installed pgvector extension. As a result, we can see what is happening transparently at each step of the RAG inquiry process.
Here we are not using a LangChain retrieval chain, the OpenAI embedding API, or the OpenAI chat model, all of which are black boxes. Here we can inspect the contents of the database table, we can see the syntax of the SQL that does the similarity search, and we can see what is returned by the search and how it is used as context to pass a query to the LLM. Even the query that we send to the LLM is modifiable.
If we compare this to the local RAG implementation we stepped through in the first article, the technology is more transparent and the steps are now granular.