Today, we are announcing the general availability of the generative engine of Amazon Polly with three voices: Ruth and Matthew in American English and Amy in British English. The new generative engine was trained with publicly available and proprietary data, a variety of voices, languages, and styles. It performs with the highest precision to render context-dependent prosody, pausing, spelling, dialectal properties, foreign word pronunciation, and more.
Amazon Polly is a machine learning (ML) service that converts text to lifelike speech, called text-to-speech (TTS) technology. Now, Amazon Polly includes high-quality, natural-sounding human-like voices in dozens of languages, so you can select the ideal voice and distribute your speech-enabled applications in many locales or countries.
With Amazon Polly, you can select various voice options, including neural, long-form, and generative voices, which deliver ground-breaking improvements in speech quality and produce human-like, highly expressive, and emotionally adept voices. You can store speech output in standard formats like MP3 or OGG, adjust the speech rate, pitch, or volume with Speech Synthesis Markup Language (SSML) tags, and quickly deliver lifelike voices and conversational user experiences with consistently fast response times.
What’s the new generative engine?
Amazon Polly now supports four voice engines: standard, neural, long-form, and generative voices.
Standard TTS voices, introduced in 2016 use traditional concatenative synthesis. This method strings together the phonemes of recorded speech, producing very natural-sounding synthesized speech. However, the inevitable variations in speech and the techniques used to segment the waveforms limit the quality of speech.
Neural TTS (NTTS) voices, introduced in 2019, use a sequence-to-sequence neural network that converts a sequence of phonemes into spectrograms, and a neural vocoder that converts the spectrograms into a continuous audio signal. The NTTS produces even higher quality human-like voices than its standard voices.
Long-form voices, introduced in 2023, are developed with cutting-edge deep learning TTS technology and designed to captivate listeners’ attention for longer content, such as news articles, training materials, or marketing videos.
In February 2024, Amazon scientists introduced a new research TTS model called Big Adaptive Streamable TTS with Emergent abilities (BASE). With this technology, Polly Generative engine is able to create human-like synthetically generated voices. You can use these voices as a knowledgeable customer assistant, a virtual trainer, or an experienced marketer.
Here are the new generative voices:
| Name | Locale | Gender | Language | Sample prompt | NTTS voices |
Generative voices |
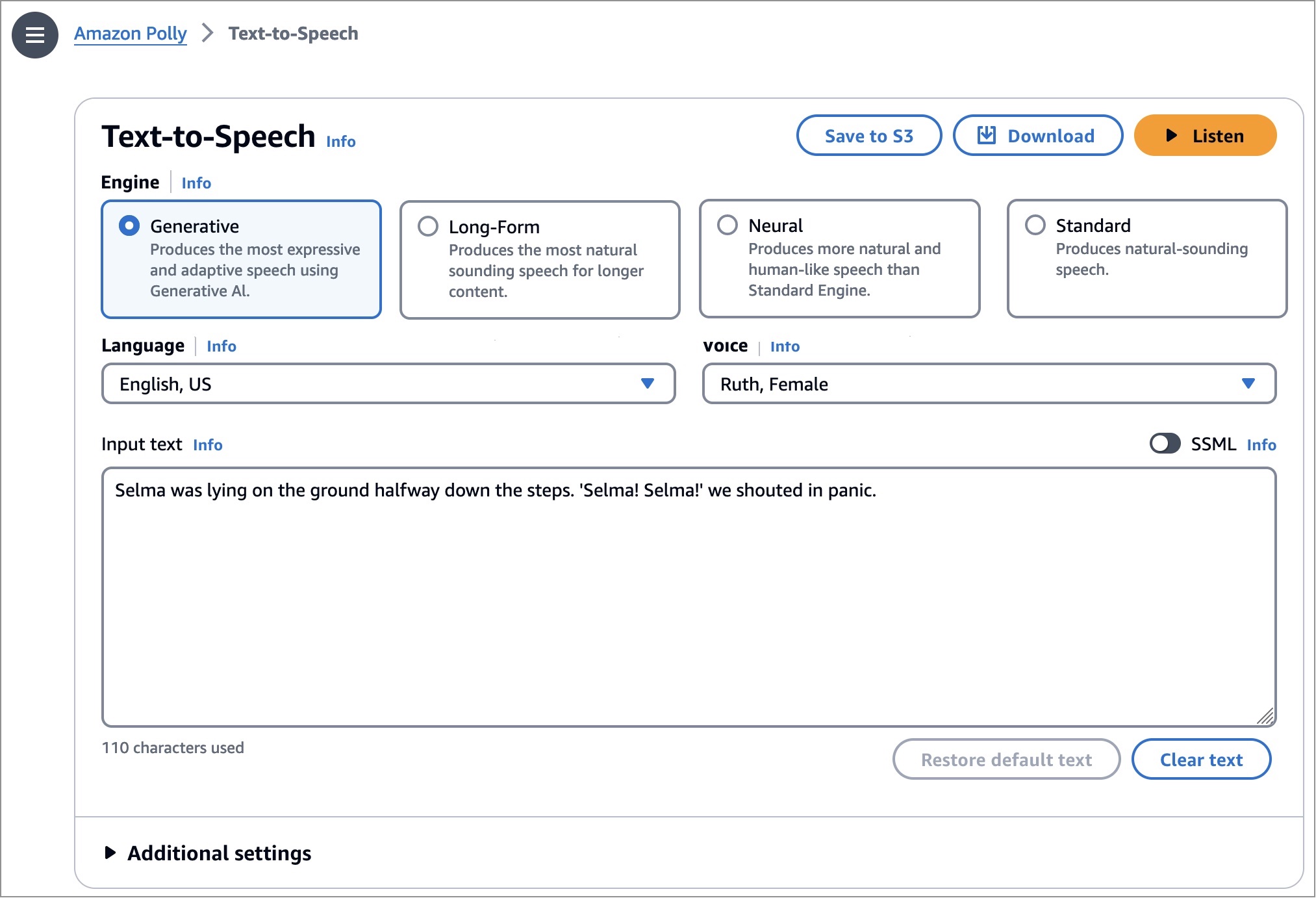
| Ruth | en_US | Female | English (US) | Selma was lying on the ground halfway down the steps. 'Selma! Selma!' we shouted in panic. |
||
| Matthew | en_US | Male | English (US) | The guards were standing outside with some of our neighbours, listening to a transistor radio. 'Any good news?' I asked. 'No, we're listening to the names of people who were killed yesterday,' Bruno replied. |
||
| Amy | en_GB | Female | English (British) | What are you looking at?' he said as he stood over me. They got off the bus and started searching the baggage compartment. The tension on the bus was like a dark, menacing cloud that hovered above us. |
You can choose from these voice options to suit your application and use case. To learn more about the generative engine, visit Generative voices in the AWS documentation.
Get started with using generative voices
You can access the new voices using the AWS Management Console, AWS Command Line Interface (AWS CLI), or the AWS SDKs.
To get started, go to the Amazon Polly console in the US (N. Virginia) Region and choose Text-to-Speech menu in the left pane. If you select the voice of Ruth or Matthew in the language of English, US or Amy in English, UK, you can choose Generative engine. Input your text and listen to or download the generated voice output.
Using the CLI, you can list the voices that use the new generative engine:
$ aws polly describe-voices --output json --region us-east-1
| jq -r '.Voices[] | select(.SupportedEngines | index("generative")) | .Name'
Matthew
Amy
RuthNow, run the synthesize-speech CLI command to synthesize sample text to an audio file (hello.mp3) with the parameters of generative engine and a supported voice ID.
$ aws polly synthesize-speech --output-format mp3 --region us-east-1
--text "Hello. This is my first generative voices!"
--voice-id Matthew --engine generative hello.mp3To learn more code examples using AWS SDKs, visit Code and Application Examples in the AWS documentation. You can use Java and Python code examples, application examples such as web applications using Java or Python, or iOS and Android applications.
Now available
The new generative voices of Amazon Polly are now available today in the US East (N. Virginia) Region. You only pay for what you use based on the number of characters of text that you convert to speech. To learn more, visit our Amazon Polly Pricing page.
Give new generative voices a try in the Amazon Polly console today and send feedback to AWS re:Post for Amazon Polly or through your usual AWS Support contacts.
— Channy