The Amazon Bedrock model evaluation capability that we previewed at AWS re:Invent 2023 is now generally available. This new capability helps you to incorporate Generative AI into your application by giving you the power to select the foundation model that gives you the best results for your particular use case. As my colleague Antje explained in her post (Evaluate, compare, and select the best foundation models for your use case in Amazon Bedrock):
Model evaluations are critical at all stages of development. As a developer, you now have evaluation tools available for building generative artificial intelligence (AI) applications. You can start by experimenting with different models in the playground environment. To iterate faster, add automatic evaluations of the models. Then, when you prepare for an initial launch or limited release, you can incorporate human reviews to help ensure quality.
We received a lot of wonderful and helpful feedback during the preview and used it to round-out the features of this new capability in preparation for today’s launch — I’ll get to those in a moment. As a quick recap, here are the basic steps (refer to Antje’s post for a complete walk-through):
Create a Model Evaluation Job – Select the evaluation method (automatic or human), select one of the available foundation models, choose a task type, and choose the evaluation metrics. You can choose accuracy, robustness, and toxicity for an automatic evaluation, or any desired metrics (friendliness, style, and adherence to brand voice, for example) for a human evaluation. If you choose a human evaluation, you can use your own work team or you can opt for an AWS-managed team. There are four built-in task types, as well as a custom type (not shown):

After you select the task type you choose the metrics and the datasets that you want to use to evaluate the performance of the model. For example, if you select Text classification, you can evaluate accuracy and/or robustness with respect to your own dataset or a built-in one:
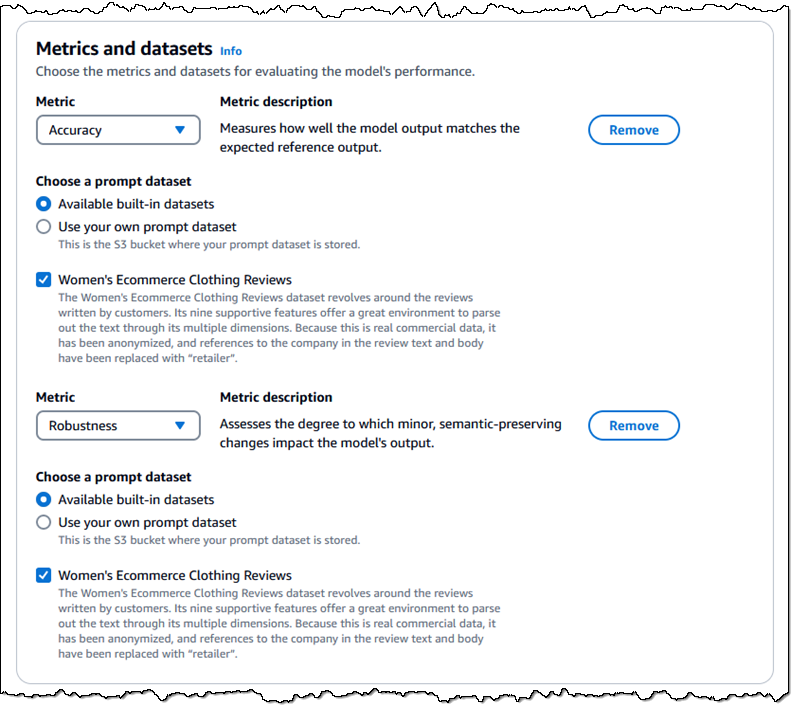
As you can see above, you can use a built-in dataset, or prepare a new one in JSON Lines (JSONL) format. Each entry must include a prompt and can include a category. The reference response is optional for all human evaluation configurations and for some combinations of task types and metrics for automatic evaluation:
You (or your local subject matter experts) can create a dataset that uses customer support questions, product descriptions, or sales collateral that is specific to your organization and your use case. The built-in datasets include Real Toxicity, BOLD, TREX, WikiText-2, Gigaword, BoolQ, Natural Questions, Trivia QA, and Women’s Ecommerce Clothing Reviews. These datasets are designed to test specific types of tasks and metrics, and can be chosen as appropriate.
Run Model Evaluation Job – Start the job and wait for it to complete. You can review the status of each of your model evaluation jobs from the console, and can also access the status using the new GetEvaluationJob API function:
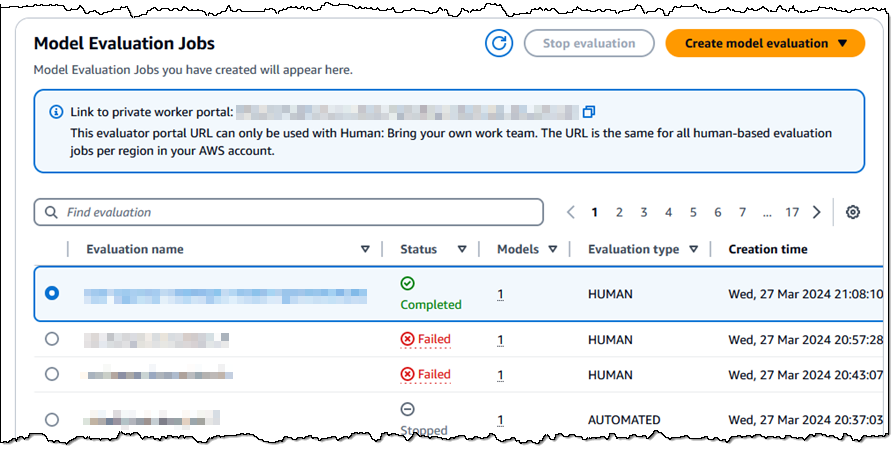
Retrieve and Review Evaluation Report – Get the report and review the model’s performance against the metrics that you selected earlier. Again, refer to Antje’s post for a detailed look at a sample report.
New Features for GA
With all of that out of the way, let’s take a look at the features that were added in preparation for today’s launch:
Improved Job Management – You can now stop a running job using the console or the new model evaluation API.
Model Evaluation API – You can now create and manage model evaluation jobs programmatically. The following functions are available:
CreateEvaluationJob– Create and run a model evaluation job using parameters specified in the API request including anevaluationConfigand aninferenceConfig.ListEvaluationJobs– List model evaluation jobs, with optional filtering and sorting by creation time, evaluation job name, and status.GetEvaluationJob– Retrieve the properties of a model evaluation job, including the status (InProgress, Completed, Failed, Stopping, or Stopped). After the job has completed, the results of the evaluation will be stored at the S3 URI that was specified in theoutputDataConfigproperty supplied toCreateEvaluationJob.StopEvaluationJob– Stop an in-progress job. Once stopped, a job cannot be resumed, and must be created anew if you want to rerun it.
This model evaluation API was one of the most-requested features during the preview. You can use it to perform evaluations at scale, perhaps as part of a development or testing regimen for your applications.
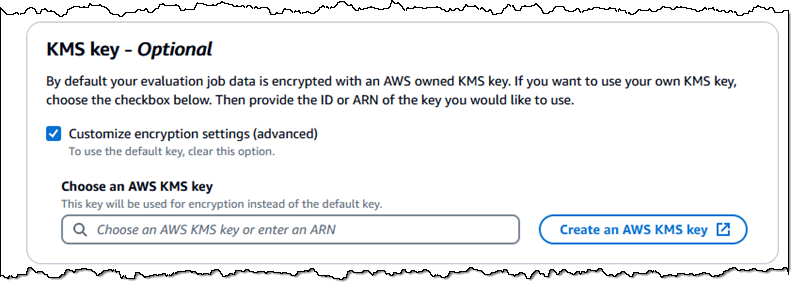
Enhanced Security – You can now use customer-managed KMS keys to encrypt your evaluation job data (if you don’t use this option, your data is encrypted using a key owned by AWS):
Access to More Models – In addition to the existing text-based models from AI21 Labs, Amazon, Anthropic, Cohere, and Meta, you now have access to Claude 2.1:
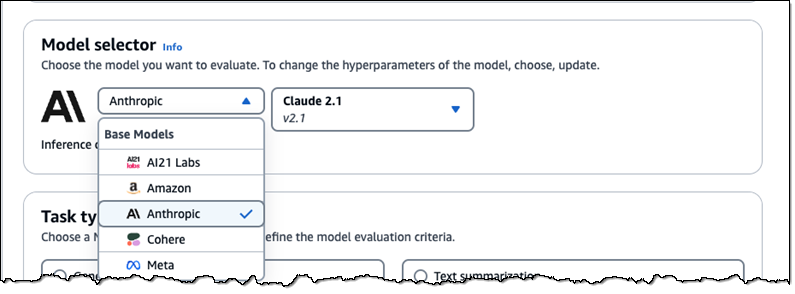
After you select a model you can set the inference configuration that will be used for the model evaluation job:
Things to Know
Here are a couple of things to know about this cool new Amazon Bedrock capability:
Pricing – You pay for the inferences that are performed during the course of the model evaluation, with no additional charge for algorithmically generated scores. If you use human-based evaluation with your own team, you pay for the inferences and $0.21 for each completed task — a human worker submitting an evaluation of a single prompt and its associated inference responses in the human evaluation user interface. Pricing for evaluations performed by an AWS managed work team is based on the dataset, task types, and metrics that are important to your evaluation. For more information, consult the Amazon Bedrock Pricing page.
Regions – Model evaluation is available in the US East (N. Virginia) and US West (Oregon) AWS Regions.
More GenAI – Visit our new GenAI space to learn more about this and the other announcements that we are making today!
— Jeff;