With Amazon Bedrock, you have access to a choice of high-performing foundation models (FMs) from leading artificial intelligence (AI) companies that make it easier to build and scale generative AI applications. Some of these models provide publicly available weights that can be fine-tuned and customized for specific use cases. However, deploying customized FMs in a secure and scalable way is not an easy task.
Starting today, Amazon Bedrock adds in preview the capability to import custom weights for supported model architectures (such as Meta Llama 2, Llama 3, and Mistral) and serve the custom model using On-Demand mode. You can import models with weights in Hugging Face safetensors format from Amazon SageMaker and Amazon Simple Storage Service (Amazon S3).
In this way, you can use Amazon Bedrock with existing customized models such as Code Llama, a code-specialized version of Llama 2 that was created by further training Llama 2 on code-specific datasets, or use your data to fine-tune models for your own unique business case and import the resulting model in Amazon Bedrock.
Let’s see how this works in practice.
Bringing a custom model to Amazon Bedrock
In the Amazon Bedrock console, I choose Imported models from the Foundation models section of the navigation pane. Now, I can create a custom model by importing model weights from an Amazon Simple Storage Service (Amazon S3) bucket or from an Amazon SageMaker model.
I choose to import model weights from an S3 bucket. In another browser tab, I download the MistralLite model from the Hugging Face website using this pull request (PR) that provides weights in safetensors format. The pull request is currently Ready to merge, so it might be part of the main branch when you read this. MistralLite is a fine-tuned Mistral-7B-v0.1 language model with enhanced capabilities of processing long context up to 32K tokens.
When the download is complete, I upload the files to an S3 bucket in the same AWS Region where I will import the model. Here are the MistralLite model files in the Amazon S3 console:

Back at the Amazon Bedrock console, I enter a name for the model and keep the proposed import job name.

I select Model weights in the Model import settings and browse S3 to choose the location where I uploaded the model weights.
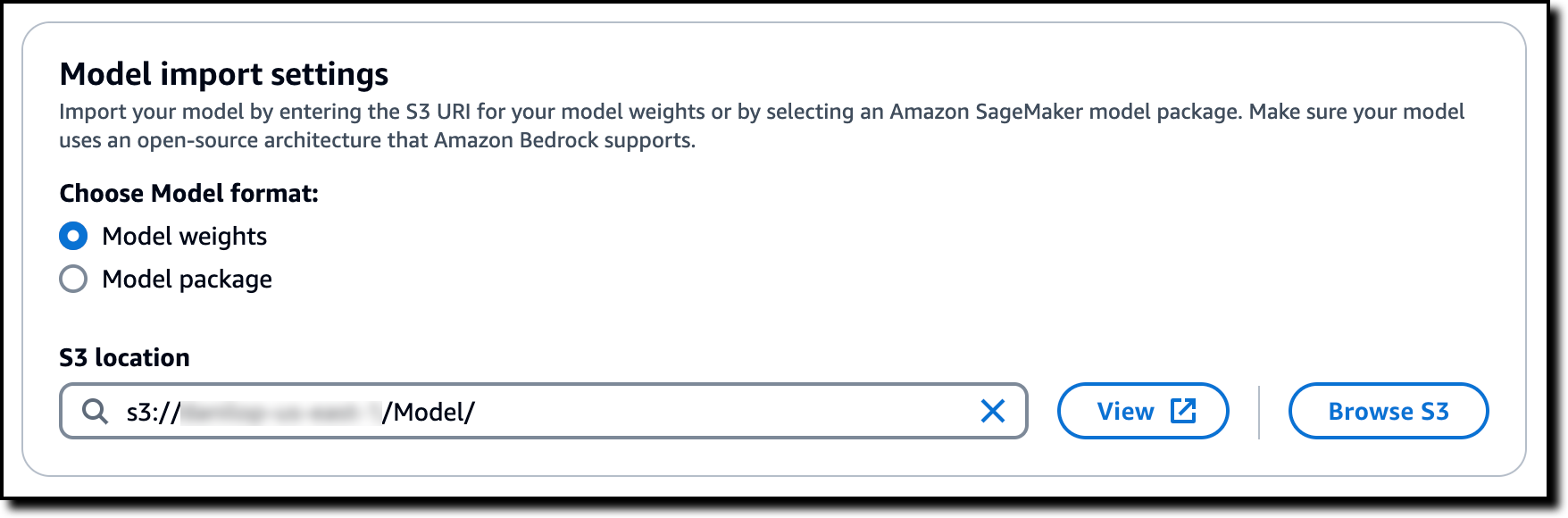
To authorize Amazon Bedrock to access the files on the S3 bucket, I select the option to create and use a new AWS Identity and Access Management (IAM) service role. I use the View permissions details link to check what will be in the role. Then, I submit the job.
About ten minutes later, the import job is completed.
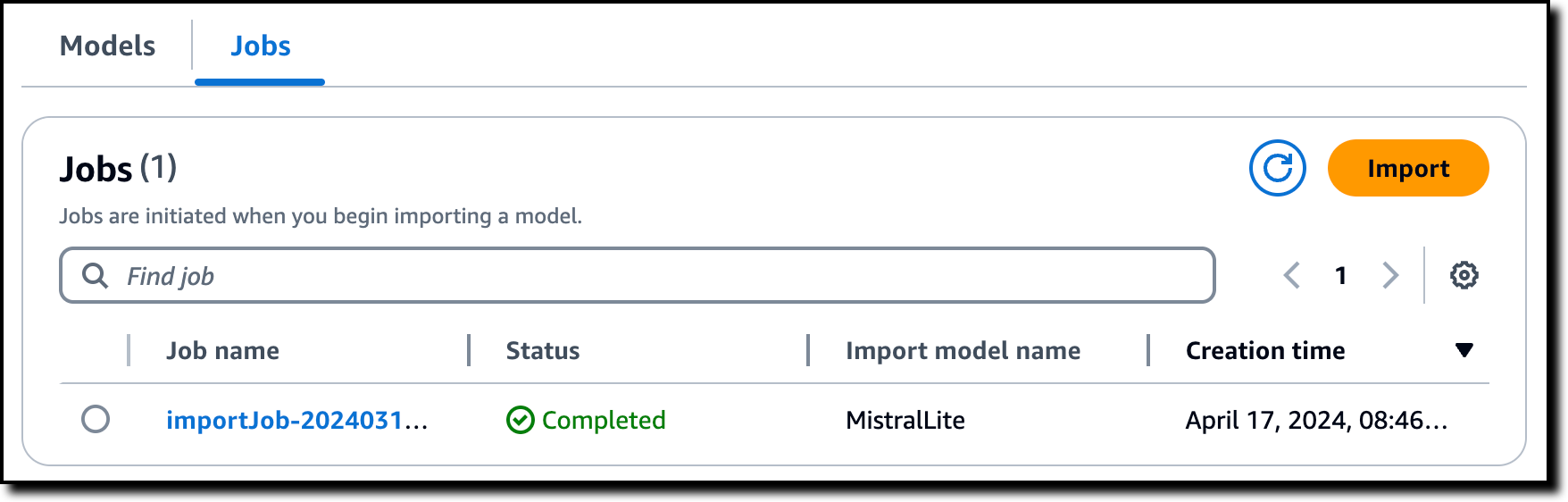
Now, I see the imported model in the console. The list also shows the model Amazon Resource Name (ARN) and the creation date.
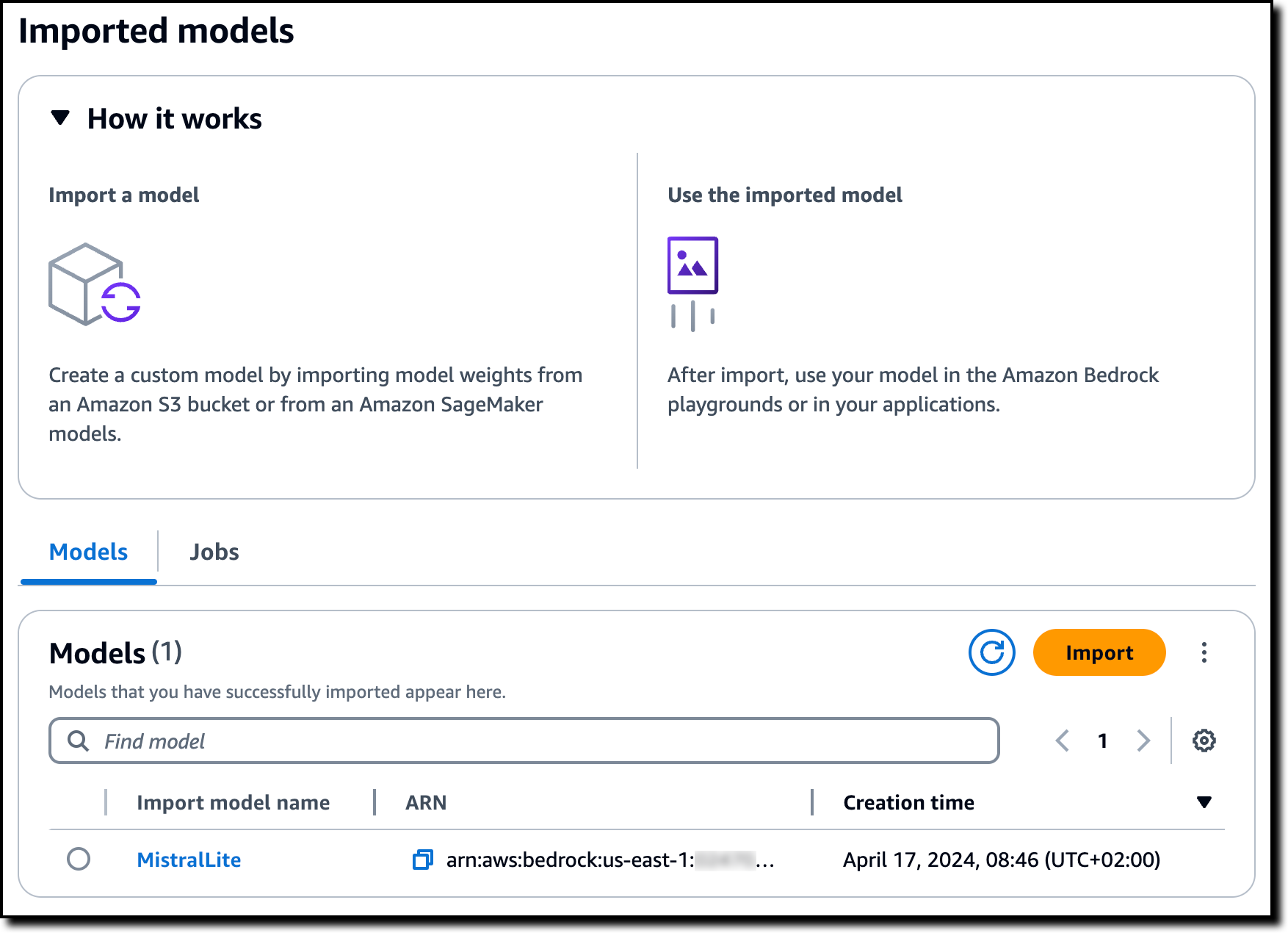
I choose the model to get more information, such as the S3 location of the model files.
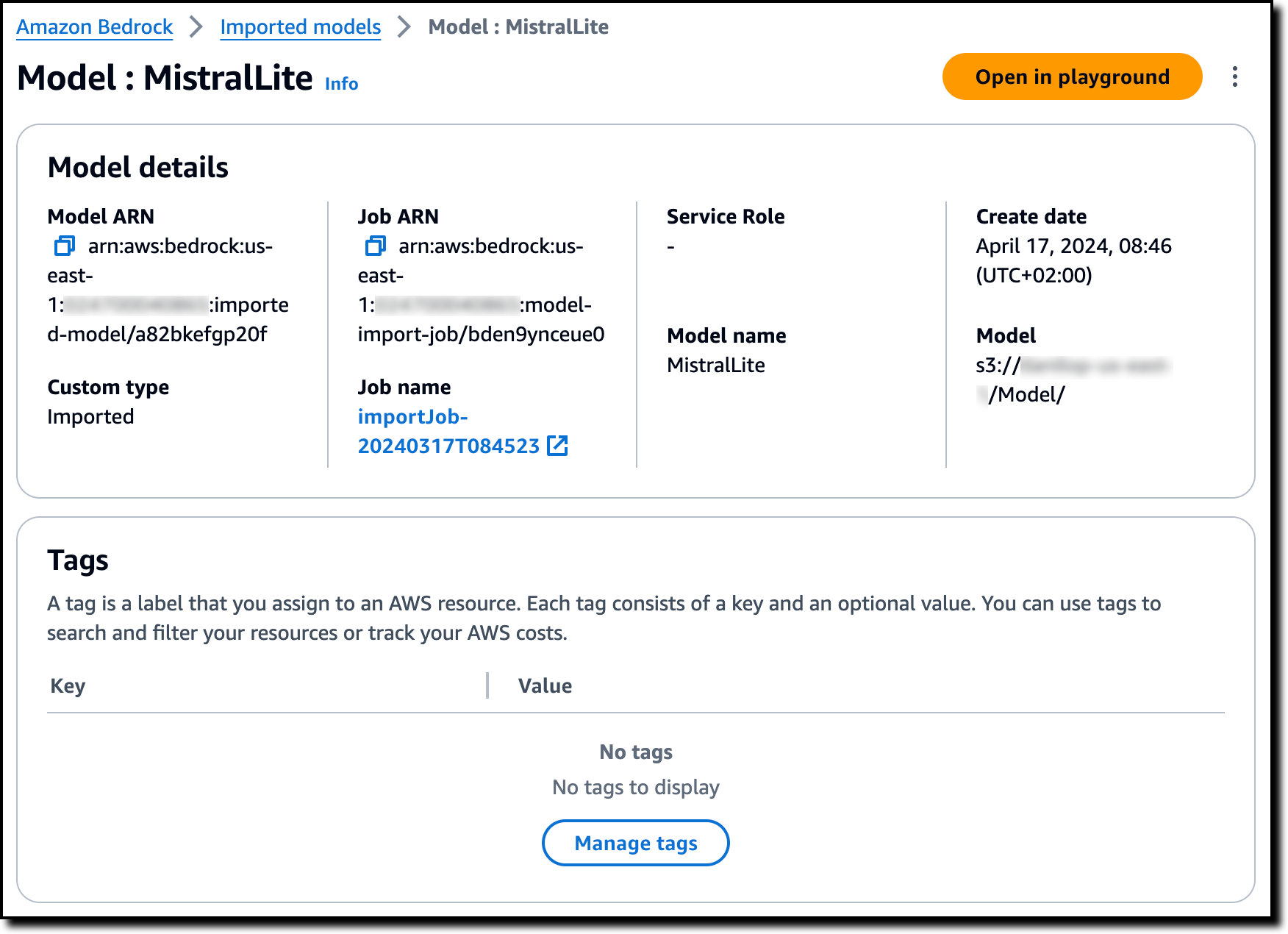
In the model detail page, I choose Open in playground to test the model in the console. In the text playground, I type a question using the prompt template of the model:
<|prompter|>What are the main challenges to support a long context for LLM?</s><|assistant|>
The MistralLite imported model is quick to reply and describe some of those challenges.

In the playground, I can tune responses for my use case using configurations such as temperature and maximum length or add stop sequences specific to the imported model.
To see the syntax of the API request, I choose the three small vertical dots at the top right of the playground.

I choose View API syntax and run the command using the AWS Command Line Interface (AWS CLI):
The output is similar to what I got in the playground. As you can see, for imported models, the model ID is the ARN of the imported model. I can use the model ID to invoke the imported model with the AWS CLI and AWS SDKs.
Things to know
You can bring your own weights for supported model architectures to Amazon Bedrock in the US East (N. Virginia) AWS Region. The model import capability is currently available in preview.
When using custom weights, Amazon Bedrock serves the model with On-Demand mode, and you only pay for what you use with no time-based term commitments. For detailed information, see Amazon Bedrock pricing.
The ability to import models is managed using AWS Identity and Access Management (IAM), and you can allow this capability only to the roles in your organization that need to have it.
With this launch, it’s now easier to build and scale generative AI applications using custom models with security and privacy built in.
To learn more:
- See the Amazon Bedrock User Guide.
- Visit our community.aws site to find deep-dive technical content and discover how others are using Amazon Bedrock in their solutions.
— Danilo