Today, we’re thrilled to announce Amazon Nova, a new generation of state-of-the-art foundation models (FMs) that deliver frontier intelligence and industry leading price performance, available exclusively in Amazon Bedrock.
You can use Amazon Nova to lower costs and latency for almost any generative AI task. You can build on Amazon Nova to analyze complex documents and videos, understand charts and diagrams, generate engaging video content, and build sophisticated AI agents, from across a range of intelligence classes optimized for enterprise workloads.
Whether you’re developing document processing applications that need to process images and text, creating marketing content at scale, or building AI assistants that can understand and act on visual information, Amazon Nova provides the intelligence and flexibility you need with two categories of models: understanding and creative content generation.
Amazon Nova understanding models accept text, image, or video inputs to generate text output. Amazon creative content generation models accept text and image inputs to generate image or video output.
Understanding models: Text and visual intelligence
The Amazon Nova models include three understanding models (with a fourth one coming soon) designed to meet different needs:
Amazon Nova Micro – A text-only model that delivers the lowest latency responses in the Amazon Nova family of models at a very low cost. With a context length of 128K tokens and optimized for speed and cost, Amazon Nova Micro excels at tasks such as text summarization, translation, content classification, interactive chat and brainstorming, and simple mathematical reasoning and coding. Amazon Nova Micro also supports customization on proprietary data using fine-tuning and model distillation to boost accuracy.
Amazon Nova Lite – A very low-cost multimodal model that is lightning fast for processing image, video, and text inputs to generate text output. Amazon Nova Lite can handle real-time customer interactions, document analysis, and visual question-answering tasks with high accuracy. The model processes inputs up to 300K tokens in length and can analyze multiple images or up to 30 minutes of video in a single request. Amazon Nova Lite also supports text and multimodal fine-tuning and can be optimized to deliver the best quality and costs for your use case with techniques such as model distillation.
Amazon Nova Pro – A highly capable multimodal model with the best combination of accuracy, speed, and cost for a wide range of tasks. Amazon Nova Pro is capable of processing up to 300K input tokens and sets new standards in multimodal intelligence and agentic workflows that require calling APIs and tools to complete complex workflows. It achieves state-of-the-art performance on key benchmarks including visual question answering (TextVQA) and video understanding (VATEX). Amazon Nova Pro demonstrates strong capabilities in processing both visual and textual information and excels at analyzing financial documents. With an input context of 300K tokens, it can process code bases with over fifteen thousand lines of code. Amazon Nova Pro also serves as a teacher model to distill custom variants of Amazon Nova Micro and Lite.
Amazon Nova Premier – Our most capable multimodal model for complex reasoning tasks and for use as the best teacher for distilling custom models. Amazon Nova Premier is still in training. We’re targeting availability in early 2025.
Amazon Nova understanding models excel in Retrieval-Augmented Generation (RAG), function calling, and agentic applications. This is reflected in Amazon Nova model scores in the Comprehensive RAG Benchmark (CRAG) evaluation, Berkeley Function Calling Leaderboard (BFCL), VisualWebBench, and Mind2Web.
What makes Amazon Nova particularly powerful for enterprises is its customization capabilities. Think of it as tailoring a suit: you start with a high-quality foundation and adjust it to fit your exact needs. You can fine-tune the models with text, image, and video to understand your industry’s terminology, align with your brand voice, and optimize for your specific use cases. For instance, a legal firm might customize Amazon Nova to better understand legal terminology and document structures.
You can see the latest benchmark scores for these models on the Amazon Nova product page.
Creative content generation: Bringing concepts to life
The Amazon Nova models also include two creative content generation models:
Amazon Nova Canvas – A state-of-the-art image generation model producing studio-quality images with precise control over style and content, including rich editing features such as inpainting, outpainting, and background removal. Amazon Nova Canvas excels on human evaluations and key benchmarks such as text-to-image faithfulness evaluation with question answering (TIFA) and ImageReward.
Amazon Nova Reel – A state-of-the-art video generation model. Using Amazon Nova Reel, you can produce short videos through text prompts and images, control visual style and pacing, and generate professional-quality video content for marketing, advertising, and entertainment. Amazon Nova Reel outperforms existing models on human evaluations of video quality and video consistency.
All Amazon Nova models include built-in safety controls and creative content generation models include watermarking capabilities to promote responsible AI use.
Let’s see how these models work in practice for a few use cases.
Using Amazon Nova Pro for document analysis
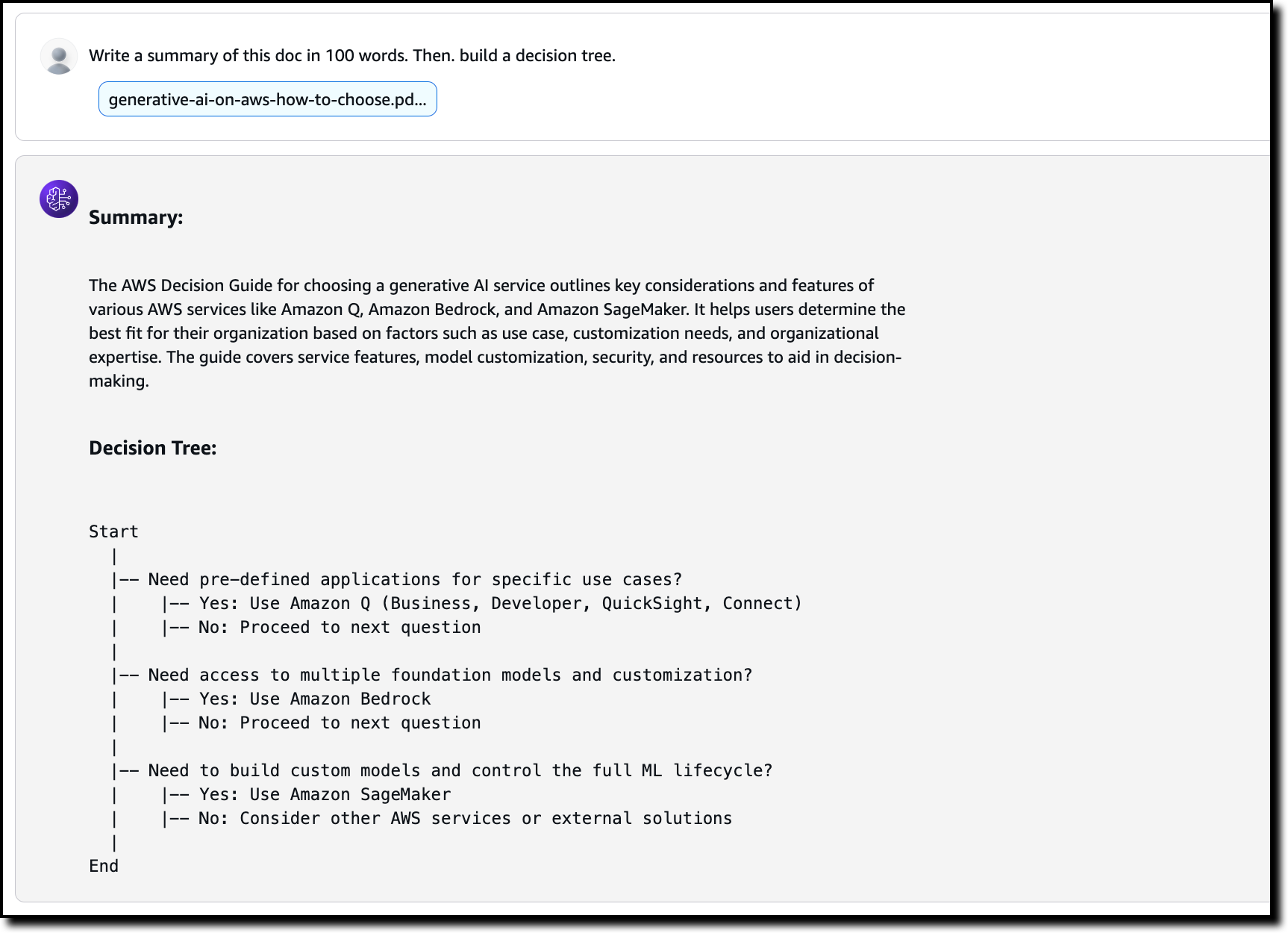
To demonstrate the capabilities of document analysis, I downloaded the Choosing a generative AI service decision guide in PDF format from the AWS documentation.
First, I choose Model access in the Amazon Bedrock console navigation pane and request access to the new Amazon Nova models. Then, I choose Chat/text in the Playground section of the navigation pane and select the Amazon Nova Pro model. In the chat, I upload the decision guide PDF and ask:
Write a summary of this doc in 100 words. Then, build a decision tree.
The output follows my instructions producing a structured decision tree that gives me a glimpse of the document before reading it.
Using Amazon Nova Pro for video analysis
To demonstrate video analysis, I prepared a video by joining two short clips (more on this in the next section):
This time, I use the AWS SDK for Python (Boto3) to invoke the Amazon Nova Pro model using the Amazon Bedrock Converse API and analyze the video:
import boto3
AWS_REGION = "us-east-1"
MODEL_ID = "amazon.nova-pro-v1:0"
VIDEO_FILE = "the-sea.mp4"
bedrock_runtime = boto3.client("bedrock-runtime", region_name=AWS_REGION)
with open(VIDEO_FILE, "rb") as f:
video = f.read()
user_message = "Describe this video."
messages = [ { "role": "user", "content": [
{"video": {"format": "mp4", "source": {"bytes": video}}},
{"text": user_message}
] } ]
response = bedrock_runtime.converse(
modelId=MODEL_ID,
messages=messages,
inferenceConfig={"temperature": 0.0}
)
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)Amazon Nova Pro can analyze videos that are uploaded with the API (as in the previous code) or that are stored in an Amazon Simple Storage Service (Amazon S3) bucket.
In the script, I ask to describe the video. I run the script from the command line. Here’s the result:
The video begins with a view of a rocky shore on the ocean, and then transitions to a close-up of a large seashell resting on a sandy beach.
I can use a more detailed prompt to extract specific information from the video such as objects or text. Note that Amazon Nova currently does not process audio in a video.
Using Amazon Nova for video creation
Now, let’s create a video using Amazon Nova Reel, starting from a text-only prompt and then providing a reference image.
Because generating a video takes a few minutes, the Amazon Bedrock API introduced three new operations:
StartAsyncInvoke – To start an asynchronous invocation
GetAsyncInvoke – To get the current status of a specific asynchronous invocation
ListAsyncInvokes – To list the status of all asynchronous invocations with optional filters such as status or date
Amazon Nova Reel supports camera control actions such as zooming or moving the camera. This Python script creates a video from this text prompt:
Closeup of a large seashell in the sand. Gentle waves flow all around the shell. Sunset light. Camera zoom in very close.
After the first invocation, the script periodically checks the status until the creation of the video has been completed. I pass a random seed to get a different result each time the code runs.
import random
import time
import boto3
AWS_REGION = "us-east-1"
MODEL_ID = "amazon.nova-reel-v1:0"
SLEEP_TIME = 30
S3_DESTINATION_BUCKET = "<BUCKET>"
video_prompt = "Closeup of a large seashell in the sand. Gentle waves flow all around the shell. Sunset light. Camera zoom in very close."
bedrock_runtime = boto3.client("bedrock-runtime", region_name=AWS_REGION)
model_input = {
"taskType": "TEXT_VIDEO",
"textToVideoParams": {"text": video_prompt},
"videoGenerationConfig": {
"durationSeconds": 6,
"fps": 24,
"dimension": "1280x720",
"seed": random.randint(0, 2147483648)
}
}
invocation = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={"s3OutputDataConfig": {"s3Uri": f"s3://{S3_DESTINATION_BUCKET}"}}
)
invocation_arn = invocation["invocationArn"]
s3_prefix = invocation_arn.split('/')[-1]
s3_location = f"s3://{S3_DESTINATION_BUCKET}/{s3_prefix}"
print(f"nS3 URI: {s3_location}")
while True:
response = bedrock_runtime.get_async_invoke(
invocationArn=invocation_arn
)
status = response["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(SLEEP_TIME)
if status == "Completed":
print(f"nVideo is ready at {s3_location}/output.mp4")
else:
print(f"nVideo generation status: {status}")I run the script:
Status: InProgress
. . .
Status: Completed
Video is ready at s3://BUCKET/PREFIX/output.mp4After a few minutes, the script completes and prints the output Amazon Simple Storage Service (Amazon S3) location. I download the output video using the AWS Command Line Interface (AWS CLI):
This is the resulting video. As requested, the camera zooms in on the subject.
Using Amazon Nova Reel with a reference image
To have better control over the creation of the video, I can provide Amazon Nova Reel a reference image such as the following:

This script uses the reference image and a text prompt with a camera action (drone view flying over a coastal landscape) to create a video:
import base64
import random
import time
import boto3
S3_DESTINATION_BUCKET = "<BUCKET>"
AWS_REGION = "us-east-1"
MODEL_ID = "amazon.nova-reel-v1:0"
SLEEP_TIME = 30
input_image_path = "seascape.png"
video_prompt = "drone view flying over a coastal landscape"
bedrock_runtime = boto3.client("bedrock-runtime", region_name=AWS_REGION)
# Load the input image as a Base64 string.
with open(input_image_path, "rb") as f:
input_image_bytes = f.read()
input_image_base64 = base64.b64encode(input_image_bytes).decode("utf-8")
model_input = {
"taskType": "TEXT_VIDEO",
"textToVideoParams": {
"text": video_prompt,
"images": [{ "format": "png", "source": { "bytes": input_image_base64 } }]
},
"videoGenerationConfig": {
"durationSeconds": 6,
"fps": 24,
"dimension": "1280x720",
"seed": random.randint(0, 2147483648)
}
}
invocation = bedrock_runtime.start_async_invoke(
modelId=MODEL_ID,
modelInput=model_input,
outputDataConfig={"s3OutputDataConfig": {"s3Uri": f"s3://{S3_DESTINATION_BUCKET}"}}
)
invocation_arn = invocation["invocationArn"]
s3_prefix = invocation_arn.split('/')[-1]
s3_location = f"s3://{S3_DESTINATION_BUCKET}/{s3_prefix}"
print(f"nS3 URI: {s3_location}")
while True:
response = bedrock_runtime.get_async_invoke(
invocationArn=invocation_arn
)
status = response["status"]
print(f"Status: {status}")
if status != "InProgress":
break
time.sleep(SLEEP_TIME)
if status == "Completed":
print(f"nVideo is ready at {s3_location}/output.mp4")
else:
print(f"nVideo generation status: {status}")Again, I download the output using the AWS CLI:
This is the resulting video. The camera starts from the reference image and moves forward.
Building AI responsibly
Amazon Nova models are built with a focus on customer safety, security, and trust throughout the model development stages, offering you peace of mind as well as an adequate level of control to enable your unique use cases.
We’ve built in comprehensive safety features and content moderation capabilities, giving you the controls you need to use AI responsibly. Every generated image and video include digital watermarking.
The Amazon Nova foundation models are built with protections that match its increased capabilities. Amazon Nova extends our safety measures to combat the spread of misinformation, child sexual abuse material (CSAM), and chemical, biological, radiological, or nuclear (CBRN) risks.
Things to know
Amazon Nova models are available in Amazon Bedrock in the US East (N. Virginia) AWS region. Amazon Nova Micro, Lite, and Pro are also available in the US West (Oregon), and US East (Ohio) regions via cross-Region inference. As usual with Amazon Bedrock, the pricing follows a pay-as-you-go model. For more information, see Amazon Bedrock pricing.
The new generation of Amazon Nova understanding models speaks your language. These models understand and generate content in over 200 languages, with particularly strong capabilities in English, German, Spanish, French, Italian, Japanese, Korean, Arabic, Simplified Chinese, Russian, Hindi, Portuguese, Dutch, Turkish, and Hebrew. This means you can build truly global applications without worrying about language barriers or maintaining separate models for different regions. Amazon Nova models for creative content generation support English prompts.
As you explore Amazon Nova, you’ll discover its ability to handle increasingly complex tasks. You can use these models to process lengthy documents up to 300K tokens, analyze multiple images in a single request, understand up to 30 minutes of video content, and generate images and videos at scale from natural language. This makes these models suitable for a variety of business use cases, from quick customer service interactions to deep analysis of corporate documentation and asset creation for advertising, ecommerce, and social media applications.
Integration with Amazon Bedrock makes deployment and scaling straightforward. You can leverage features like Amazon Bedrock Knowledge Bases to enhance your model with proprietary information, use Amazon Bedrock Agents to automate complex workflows, and implement Amazon Bedrock Guardrails to promote responsible AI use. The platform supports real-time streaming for interactive applications, batch processing for high-volume workloads, and detailed monitoring to help you optimize performance.
Ready to start building with Amazon Nova? Give the new models a try in the Amazon Bedrock console today, visit the Amazon Nova models section of the Amazon Bedrock documentation, and send feedback to AWS re:Post for Amazon Bedrock. You can find deep-dive technical content and discover how our Builder communities are using Amazon Bedrock at community.aws. Let us know what you build with these new models!
— Danilo