Today we are announcing the general availability to connect and query your existing MySQL and PostgreSQL databases with support for AWS Cloud Development Kit (AWS CDK), a new feature to create a real-time, secure GraphQL API for your relational database within or outside Amazon Web Services (AWS). You can now generate the entire API for all relational database operations with just your database endpoint and credentials. When your database schema changes, you can run a command to apply the latest table schema changes.
In 2021, we announced AWS Amplify GraphQL Transformer version 2, enabling developers to develop more feature-rich, flexible, and extensible GraphQL-based app backends even with minimal cloud expertise. This new GraphQL Transformer was redesigned from the ground up to generate extensible pipeline resolvers to route a GraphQL API request, apply business logic, such as authorization, and communicate with the underlying data source, such as Amazon DynamoDB.
However, customers wanted to use relational database sources for their GraphQL APIs such as their Amazon RDS or Amazon Aurora databases in addition to Amazon DynamoDB. You can now use @model types of Amplify GraphQL APIs for both relational database and DynamoDB data sources. Relational database information is generated to a separate schema.sql.graphql file. You can continue to use the regular schema.graphql files to create and manage DynamoDB-backed types.
When you simply provide any MySQL or PostgreSQL database information, whether behind a virtual private cloud (VPC) or publicly accessible on the internet, AWS Amplify automatically generates a modifiable GraphQL API that securely connects to your database tables and exposes create, read, update, or delete (CRUD) queries and mutations. You can also rename your data models to be more idiomatic for the frontend. For example, a database table is called “todos” (plural, lowercase) but is exposed as “ToDo” (singular, PascalCase) to the client.
With one line of code, you can add any of the existing Amplify GraphQL authorization rules to your API, making it seamless to build use cases such as owner-based authorization or public read-only patterns. Because the generated API is built on AWS AppSync‘ GraphQL capabilities, secure real-time subscriptions are available out of the box. You can subscribe to any CRUD events from any data model with a few lines of code.
Getting started with your MySQL database in AWS CDK
The AWS CDK lets you build reliable, scalable, cost-effective applications in the cloud with the considerable expressive power of a programming language. To get started, install the AWS CDK on your local machine.
$ npm install -g aws-cdkRun the following command to verify the installation is correct and print the version number of the AWS CDK.
$ cdk –versionNext, create a new directory for your app:
$ mkdir amplify-api-cdk
$ cd amplify-api-cdkInitialize a CDK app by using the cdk init command.
$ cdk init app --language typescriptInstall Amplify’s GraphQL API construct in the new CDK project:
$ npm install @aws-amplify/graphql-api-constructOpen the main stack file in your CDK project (usually located in lib/<your-project-name>-stack.ts). Import the necessary constructs at the top of the file:
import {
AmplifyGraphqlApi,
AmplifyGraphqlDefinition
} from '@aws-amplify/graphql-api-construct';Generate a GraphQL schema for a new relational database API by executing the following SQL statement on your MySQL database. Make sure to output the results to a .csv file, including column headers, and replace <database-name> with the name of your database, schema, or both.
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME,
INFORMATION_SCHEMA.COLUMNS.COLUMN_NAME,
INFORMATION_SCHEMA.COLUMNS.COLUMN_DEFAULT,
INFORMATION_SCHEMA.COLUMNS.ORDINAL_POSITION,
INFORMATION_SCHEMA.COLUMNS.DATA_TYPE,
INFORMATION_SCHEMA.COLUMNS.COLUMN_TYPE,
INFORMATION_SCHEMA.COLUMNS.IS_NULLABLE,
INFORMATION_SCHEMA.COLUMNS.CHARACTER_MAXIMUM_LENGTH,
INFORMATION_SCHEMA.STATISTICS.INDEX_NAME,
INFORMATION_SCHEMA.STATISTICS.NON_UNIQUE,
INFORMATION_SCHEMA.STATISTICS.SEQ_IN_INDEX,
INFORMATION_SCHEMA.STATISTICS.NULLABLE
FROM INFORMATION_SCHEMA.COLUMNS
LEFT JOIN INFORMATION_SCHEMA.STATISTICS ON INFORMATION_SCHEMA.COLUMNS.TABLE_NAME=INFORMATION_SCHEMA.STATISTICS.TABLE_NAME AND INFORMATION_SCHEMA.COLUMNS.COLUMN_NAME=INFORMATION_SCHEMA.STATISTICS.COLUMN_NAME
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = '<database-name>';
Run the following command, replacing <path-schema.csv> with the path to the .csv file created in the previous step.
$ npx @aws-amplify/cli api generate-schema
--sql-schema <path-to-schema.csv>
--engine-type mysql –out lib/schema.sql.graphqlYou can open schema.sql.graphql file to see the imported data model from your MySQL database schema.
input AMPLIFY {
engine: String = "mysql"
globalAuthRule: AuthRule = {allow: public}
}
type Meals @model {
id: Int! @primaryKey
name: String!
}
type Restaurants @model {
restaurant_id: Int! @primaryKey
address: String!
city: String!
name: String!
phone_number: String!
postal_code: String!
...
}If you haven’t already done so, go to the Parameter Store in the AWS Systems Manager console and create a parameter for the connection details of your database, such as hostname/url, database name, port, username, and password. These will be required in the next step for Amplify to successfully connect to your database and perform GraphQL queries or mutations against it.
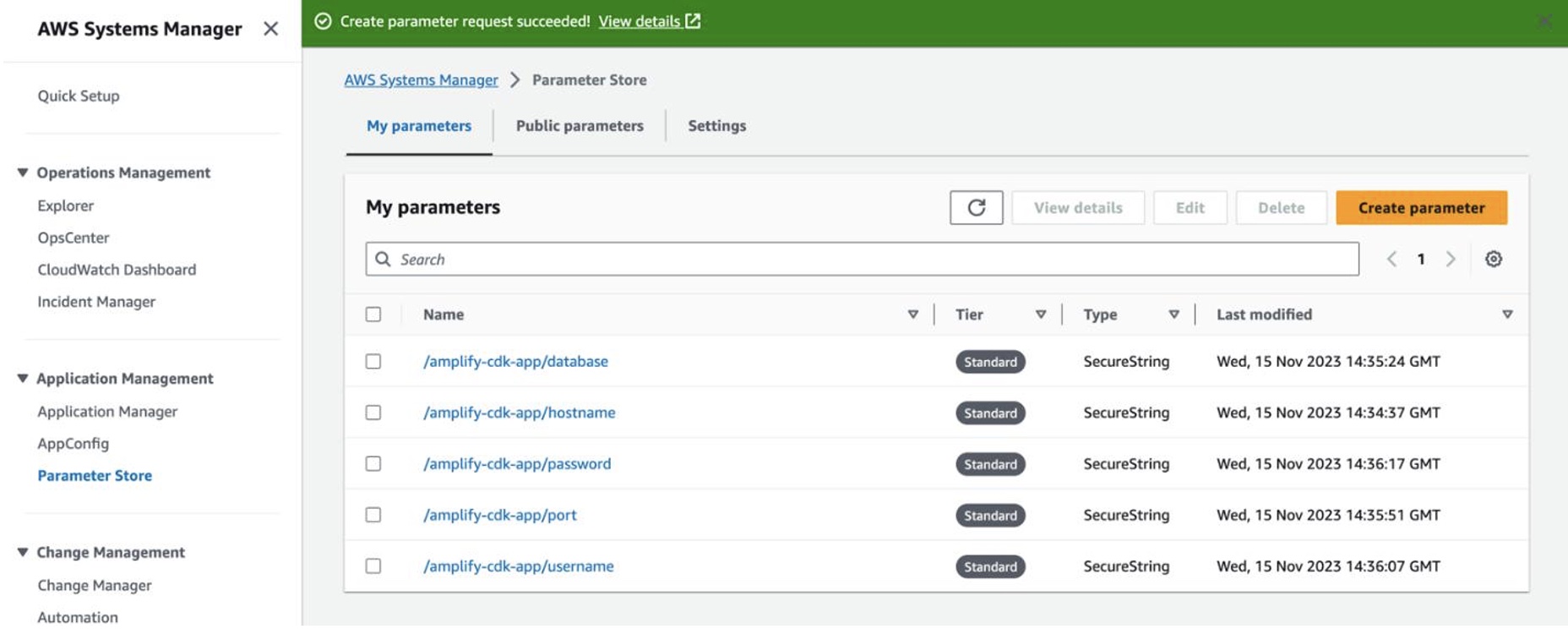
In the main stack class, add the following code to define a new GraphQL API. Replace the dbConnectionConfg options with the parameter paths created in the previous step.
new AmplifyGraphqlApi(this, "MyAmplifyGraphQLApi", {
apiName: "MySQLApi",
definition: AmplifyGraphqlDefinition.fromFilesAndStrategy(
[path.join(__dirname, "schema.sql.graphql")],
{
name: "MyAmplifyGraphQLSchema",
dbType: "MYSQL",
dbConnectionConfig: {
hostnameSsmPath: "/amplify-cdk-app/hostname",
portSsmPath: "/amplify-cdk-app/port",
databaseNameSsmPath: "/amplify-cdk-app/database",
usernameSsmPath: "/amplify-cdk-app/username",
passwordSsmPath: "/amplify-cdk-app/password",
},
}
),
authorizationModes: { apiKeyConfig: { expires: cdk.Duration.days(7) } },
translationBehavior: { sandboxModeEnabled: true },
});This configuration assums that your database is accessible from the internet. Also, the default authorization mode is set to Api Key for AWS AppSync and the sandbox mode is enabled to allow public access on all models. This is useful for testing your API before adding more fine-grained authorization rules.
Finally, deploy your GraphQL API to AWS Cloud.
$ cdk deployYou can now go to the AWS AppSync console and find your created GraphQL API.
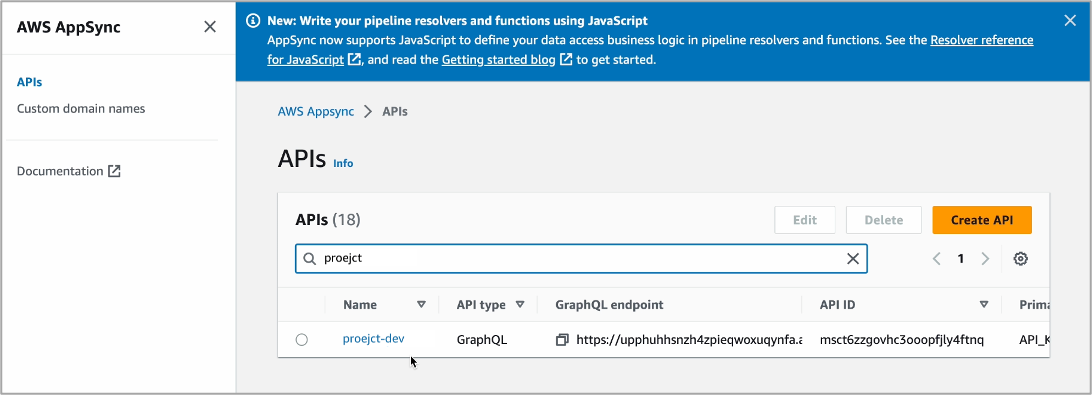
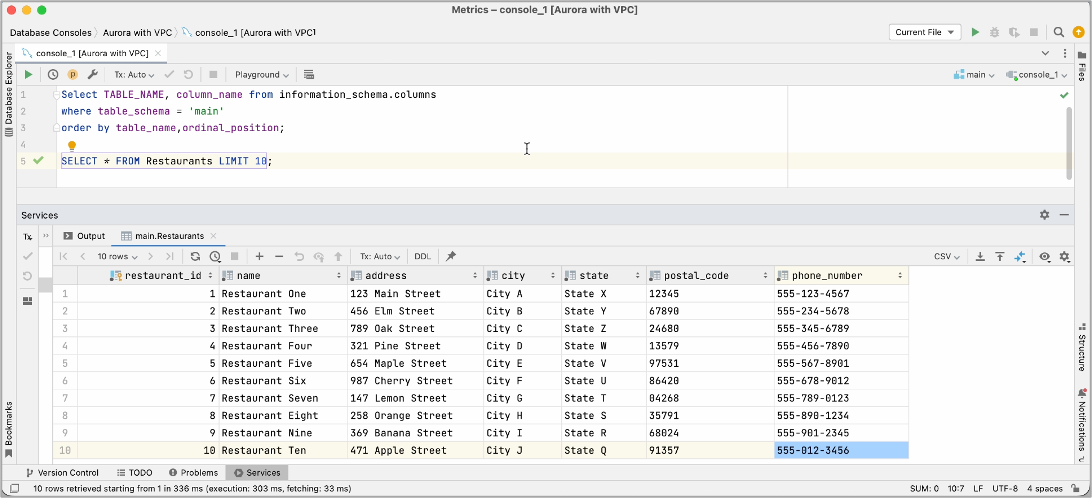
Choose your project and the Queries menu. You can see newly created GraphQL APIs compatible with your tables of MySQL database, such as getMeals to get one item or listRestaurants to list all items.
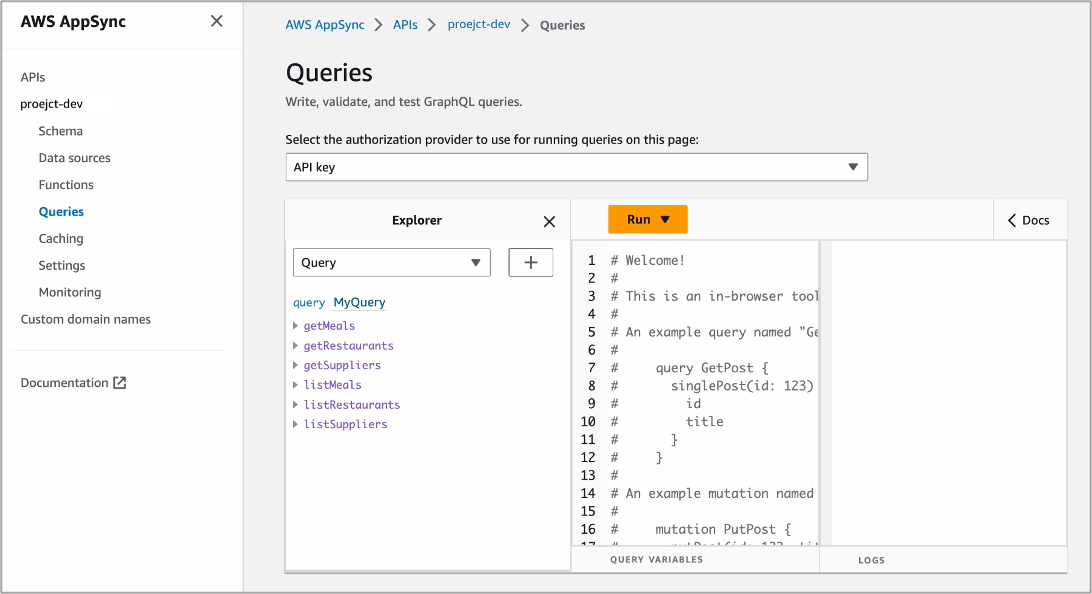
For example, when you select items with fields of address, city, name, phone_number, and so on, you can see a new GraphQL query. Choose the Run button and you can see the query results from your MySQL database.
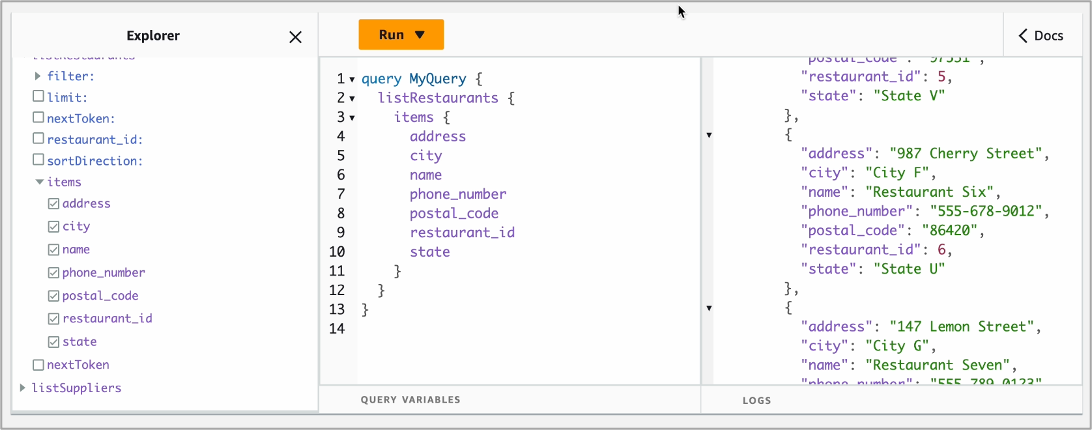
When you query your MySQL database, you can see the same results.
How to customize your GraphQL schema for your database
To add a custom query or mutation in your SQL, open the generated schema.sql.graphql file and use the @sql(statement: "") pass in parameters using the :<variable> notation.
type Query {
listRestaurantsInState(state: String): Restaurants @sql("SELECT * FROM Restaurants WHERE state = :state;”)
}For longer, more complex SQL queries, you can reference SQL statements in the customSqlStatements config option. The reference value must match the name of a property mapped to a SQL statement. In the following example, a searchPosts property on customSqlStatements is being referenced:
type Query {
searchPosts(searchTerm: String): [Post]
@sql(reference: "searchPosts")
}Here is how the SQL statement is mapped in the API definition.
new AmplifyGraphqlApi(this, "MyAmplifyGraphQLApi", {
apiName: "MySQLApi",
definition: AmplifyGraphqlDefinition.fromFilesAndStrategy( [path.join(__dirname, "schema.sql.graphql")],
{
name: "MyAmplifyGraphQLSchema",
dbType: "MYSQL",
dbConnectionConfig: {
// ...ssmPaths,
}, customSqlStatements: {
searchPosts: // property name matches the reference value in schema.sql.graphql
"SELECT * FROM posts WHERE content LIKE CONCAT('%', :searchTerm, '%');",
},
}
),
//...
});
The SQL statement will be executed as if it were defined inline in the schema. The same rules apply in terms of using parameters, ensuring valid SQL syntax, and matching return types. Using a reference file keeps your schema clean and allows the reuse of SQL statements across fields. It is best practice for longer, more complicated SQL queries.
Or you can change a field and model name using the @refersTo directive. If you don’t provide the @refersTo directive, AWS Amplify assumes that the model name and field name exactly match the database table and column names.
type Todo @model @refersTo(name: "todos") {
content: String
done: Boolean
}When you want to create relationships between two database tables, use the @hasOne and @hasMany directives to establish a 1:1 or 1:M relationship. Use the @belongsTo directive to create a bidirectional relationship back to the relationship parent. For example, you can make a 1:M relationship between a restaurant and its meals menus.
type Meals @model {
id: Int! @primaryKey
name: String!
menus: [Restaurants] @hasMany(references: ["restaurant_id"])
}
type Restaurants @model {
restaurant_id: Int! @primaryKey
address: String!
city: String!
name: String!
phone_number: String!
postal_code: String!
meals: Meals @belongsTo(references: ["restaurant_id"])
...
}Whenever you make any change to your GraphQL schema or database schema in your DB instances, you should deploy your changes to the cloud:
Whenever you make any change to your GraphQL schema or database schema in your DB instances, you should re-run the SQL script and export to .csv step mentioned earlier in this guide to re-generate your schema.sql.graphql file and then deploy your changes to the cloud:
$ cdk deploy
To learn more, see Connect API to existing MySQL or PostgreSQL database in the AWS Amplify documentation.
Now available
The relational database support for AWS Amplify now works with any MySQL and PostgreSQL databases hosted anywhere within Amazon VPC or even outside of AWS Cloud.
Give it a try and send feedback to AWS re:Post for AWS Amplify, the GitHub repository of Amplify GraphQL API, or through your usual AWS Support contacts.
— Channy
P.S. Specially thanks to René Huangtian Brandel, a principal product manager at AWS for his contribution to write sample codes.