Thanks to AI, speaking out loud has become a primary way of not only communicating with machines (like when you tell your smartphone to send a text or ask your smart speaker about the weather), but also enriching human interactions (such as generating captions in near real-time during a video meeting).
In this post, we’ll explore some of the most interesting and practical applications of speech technology, as well as the Google Cloud tools that make building these sorts of apps possible.
Captioning
Generating captions is one of the simplest and most useful applications of speech-to-text (STT) technology—so useful, in fact, that this feature is built directly into YouTube. With the click of a button, content creators can use Google’s internal STT models to generate captions for their videos, so they can be enjoyed with or without audio.
You can easily create this functionality in your own app, either with the Google Cloud Speech API for pure audio, or the Video Intelligence APIfor transcribing videos. These APIs give you not only a transcription of audio, but also timestamps so that you can link these transcriptions back to the original content. To see how to use this API to automatically generate subtitles, check out this awesome video:

Real-Time Captioning
Speech-to-Text can be done before content is created (i.e., captioning videos before they’re ever posted), but also in real time, on the fly, from generating captions during a meeting to transcribing a keynote speaker’s words as they present. This is a feature that’s already built into Google Chat:
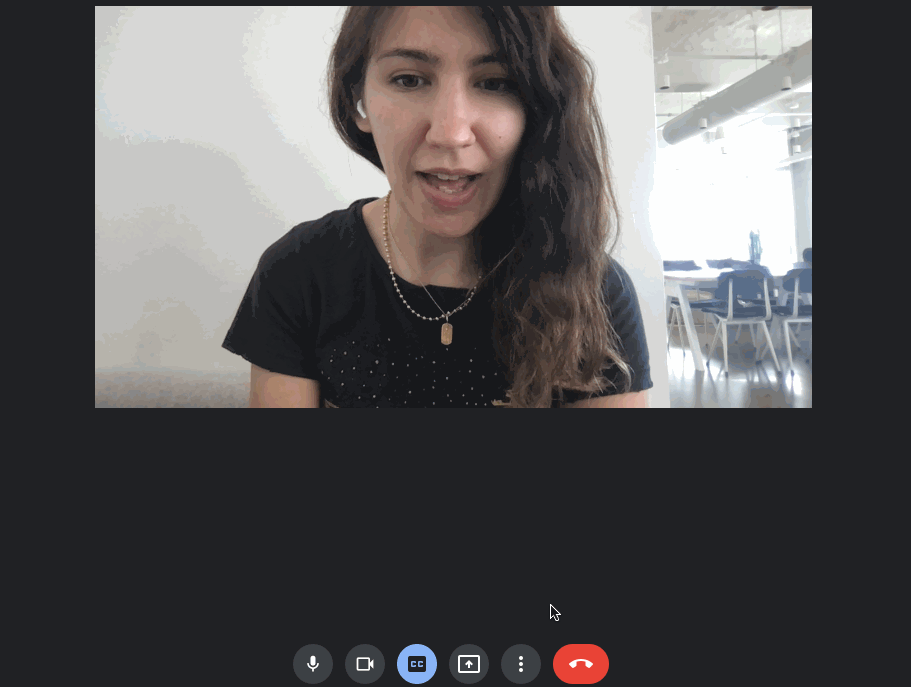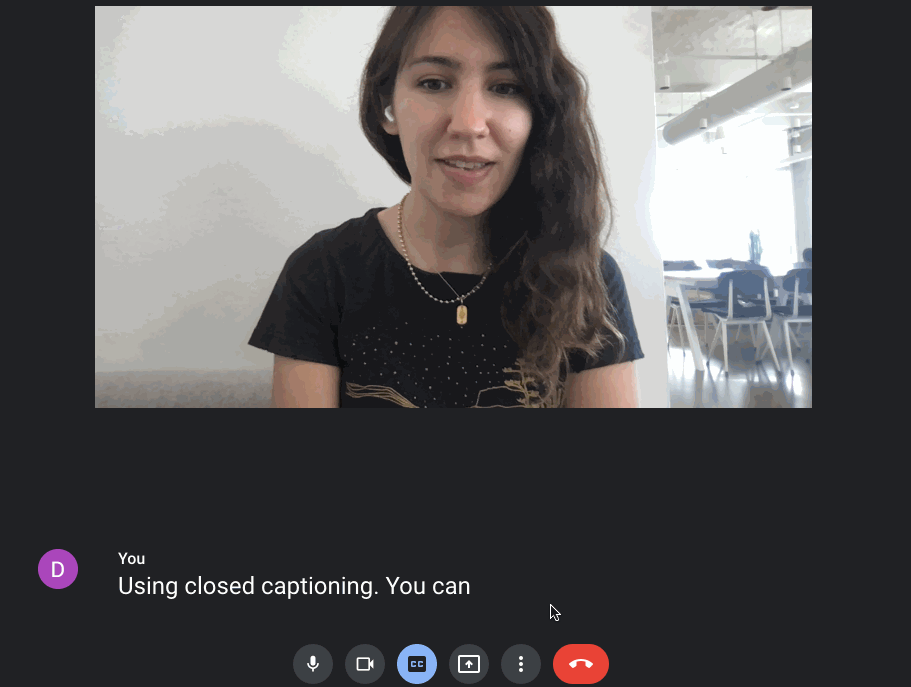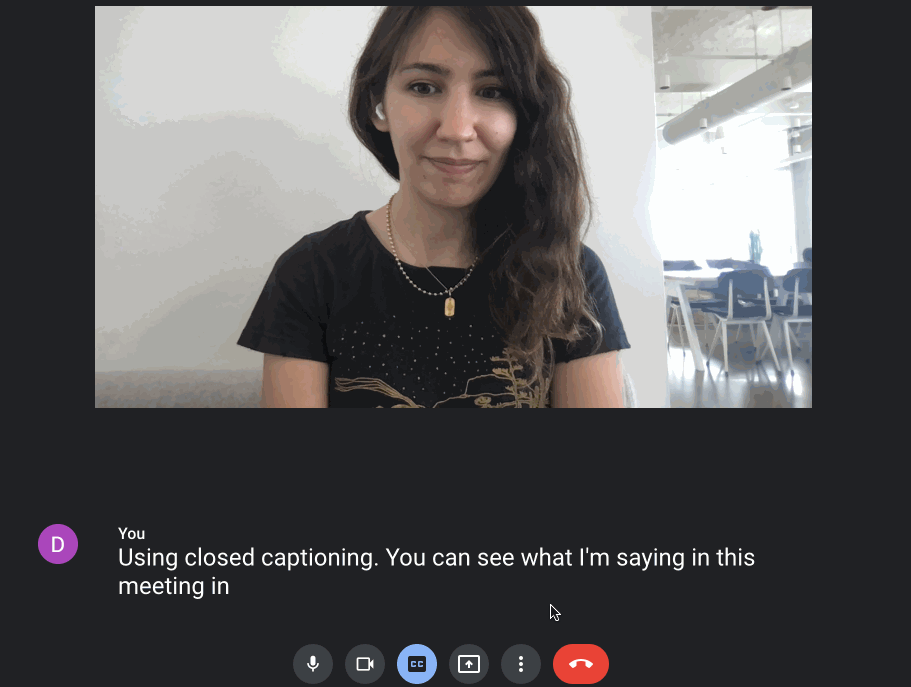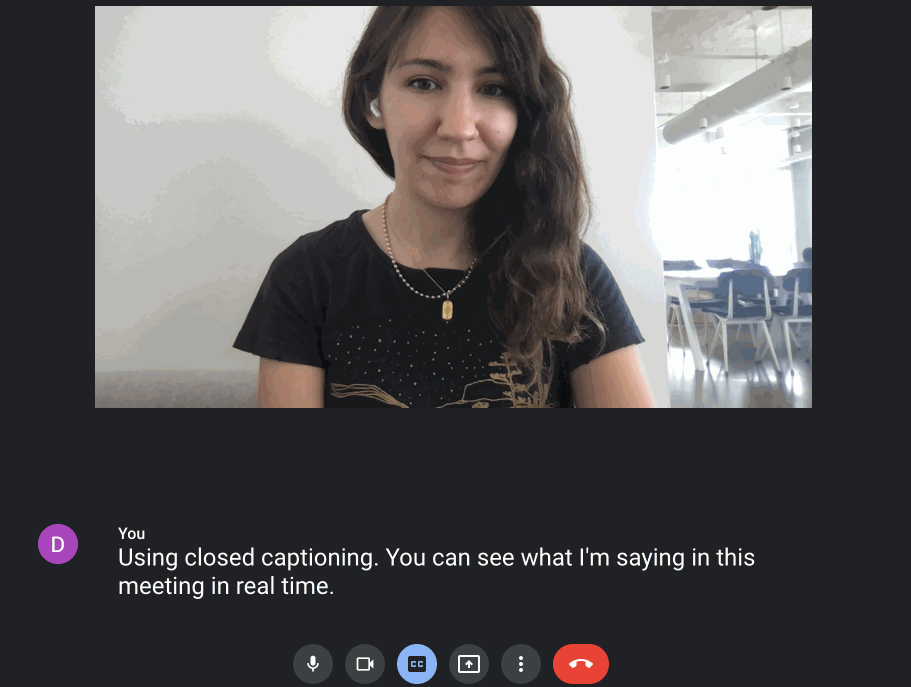
Developers can also build out this real-time functionality with Google Cloud’s Speech API. In this setup, audio is continuously streamed to the Speech endpoint. The endpoint returns intermediary transcriptions and ultimately resolves a “final” transcription when the speaker pauses.
Translating Speech
Captioning is useful in and of itself, but text transcripts are also extremely helpful in that they allow us to apply additional machine learning models on top of that text, for more sophisticated use cases.
Take translation. Just as we can use AI-powered Speech-to-Text models to automatically transcribe audio, so too can we use AI-powered Translation models (like the Google Translate API) to automatically translate that text into over 100 supported languages.
This use case is so common, in fact, that Google Cloud provides an additional API–the Media Translation API–for doing just this: transcribing and translating audio at the same time. It can also be used in a real-time, streaming scenario, like this:

Combining STT and Translation, we can create auto-generated, translated captions. We can also go a step further and add Text-to-Speech (TTS), so that we can create AI-generated dubs (voice translations), like so:

This application works by combining the Speech-to-Text API, the Translation API, and the Text-to-Speech API. Read how to build your own AI dubber here.
Speech Meets NLP
The field of Natural Language Processing (NLP) — computers’ abilities to understand human language — is becoming increasingly advanced. Once we’ve transcribed audio into text, we can begin to apply these modern NLP techniques to that transcription data, like:

For example, the STT API’s built-in “content filtering” feature lets you automatically detect profanity in text transcriptions and, optionally, filter out those profane words. Combined with the STT API, the Natural Language API’s sentiment analysis feature can tell you whether an audio transcript is expressing negative or positive emotion.
One of the most successful examples of using this tech together is in smart call centers. If you’ve ever modified an airline flight by talking to a virtual agent, you’ve seen speech and NLP at work.
Beyond powering virtual call center agents, this technology can be used to understand hundreds of thousands of hours of conversations between call centers and customers. After those conversations are transcribed with STT, NLP can be used to make those conversations easy to search (like Google search, but for phone conversations), which helps call centers to better serve customers.
For example, sentiment analysis models can detect whether customers are expressing positive or negative sentiment on calls. Entity extraction can identify specific “entities” discussed during a call, which might include the names of specific products, people, technologies, addresses, currency, etc. Topic modeling can help identify recurring conversational topics (e.g., a surge of customers calling with complaints about “billing”). And finally, text classification models can help group conversations into categories, like “bug report,” “billing,” etc.
Google’s Contact Center AI (CCAI) packages these abilities into a single offering. This includes Dialogflow CX, which makes it easy to build smart virtual agents; Agent Assist, which uses speech and NLP to assist live human agents in real time, and CCAI Insights, which helps contact center stakeholders monitor patterns in their contact center data. Want to see for yourself? Check out this video:

Beyond call centers, the potential applications of speech and NLP are truly endless, from searchable video archives to healthcare insights.
Voice-Driven Interfaces
So far, we’ve talked about how we can use the STT API to transcribe audio, and how we can apply NLP to understand and transform those transcriptions. As CCAI may suggest, one of the most exciting applications of these technologies is apps that are entirely controlled by voice. If you’ve ever told your smart speaker to turn off your bedroom lights while you’re tucked into bed, you know what I mean.
Voice-driven interfaces allow us to interact with technology that lacks screen real estate. Think smartwatches, smart speakers, apps you can control while driving your car, or virtual agents that help you change your flight over the phone.
To build voice apps like these, you need software that understands not just what words are said, but also what those words mean. That is, you need machine learning models that recognize user intent. Sometimes, that’s as simple as an app recognizing a command (i.e., “turn off the lights”). Other times, we may require more complex voice interfaces, such as ones that can handle multi-turn conversations. For this, we require Conversational AI. To learn more about Conversational AI and how chatbots and speech can be combined to build intelligent voice-driven interfaces, check out this talk:

Or, visit the Conversational AI learning hub.
Getting Started
It’s easy to try Google Cloud’s Speech-to-Text API in the Speech console. Just upload an audio file (or link to an audio file stored in Google Cloud Storage) to generate transcripts:
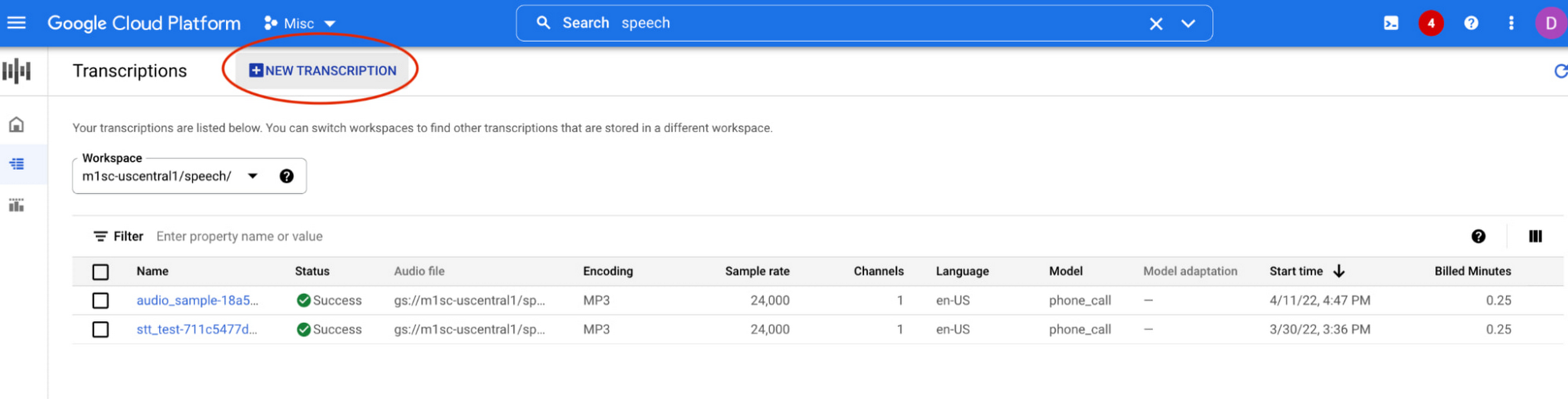
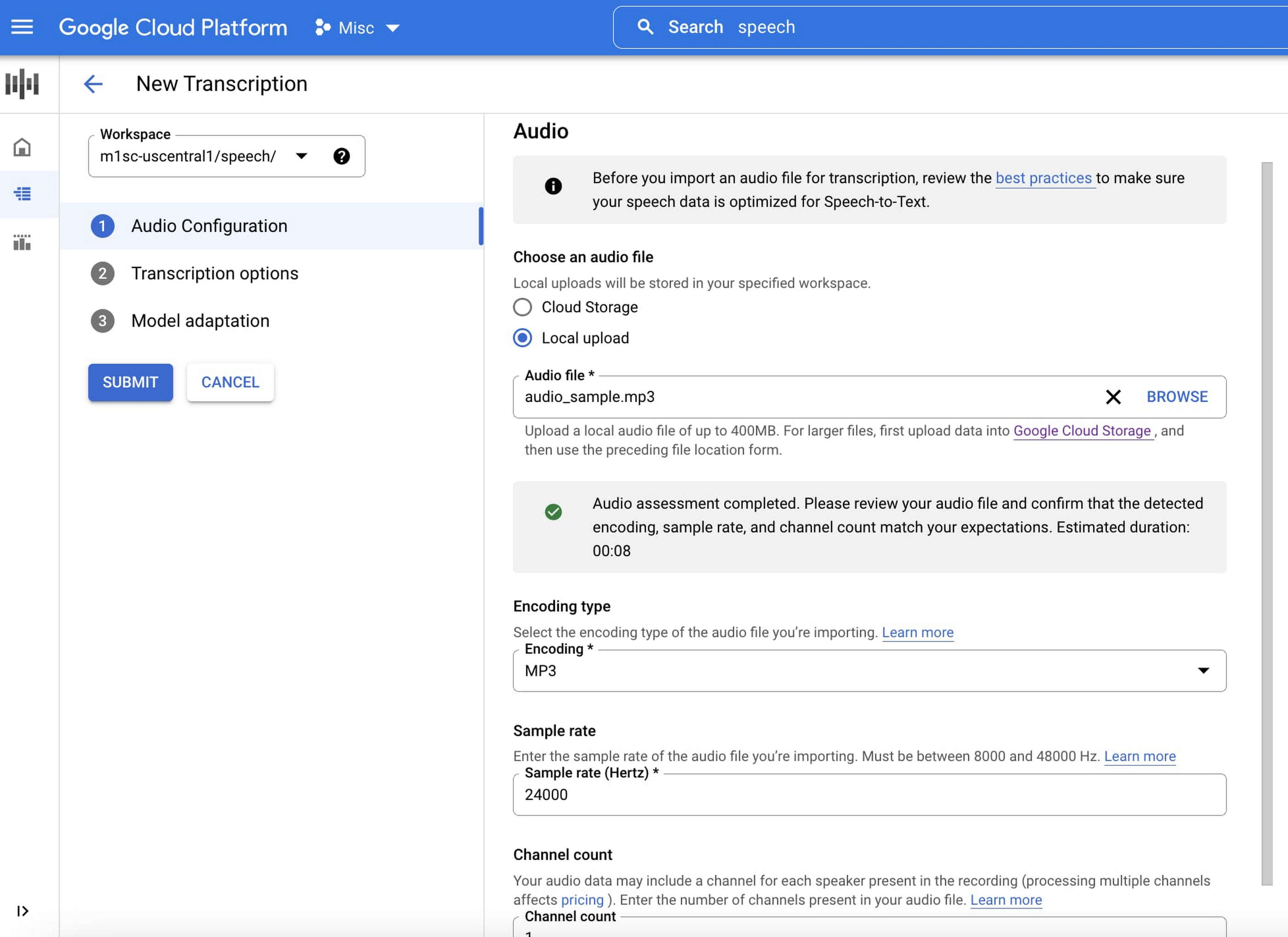
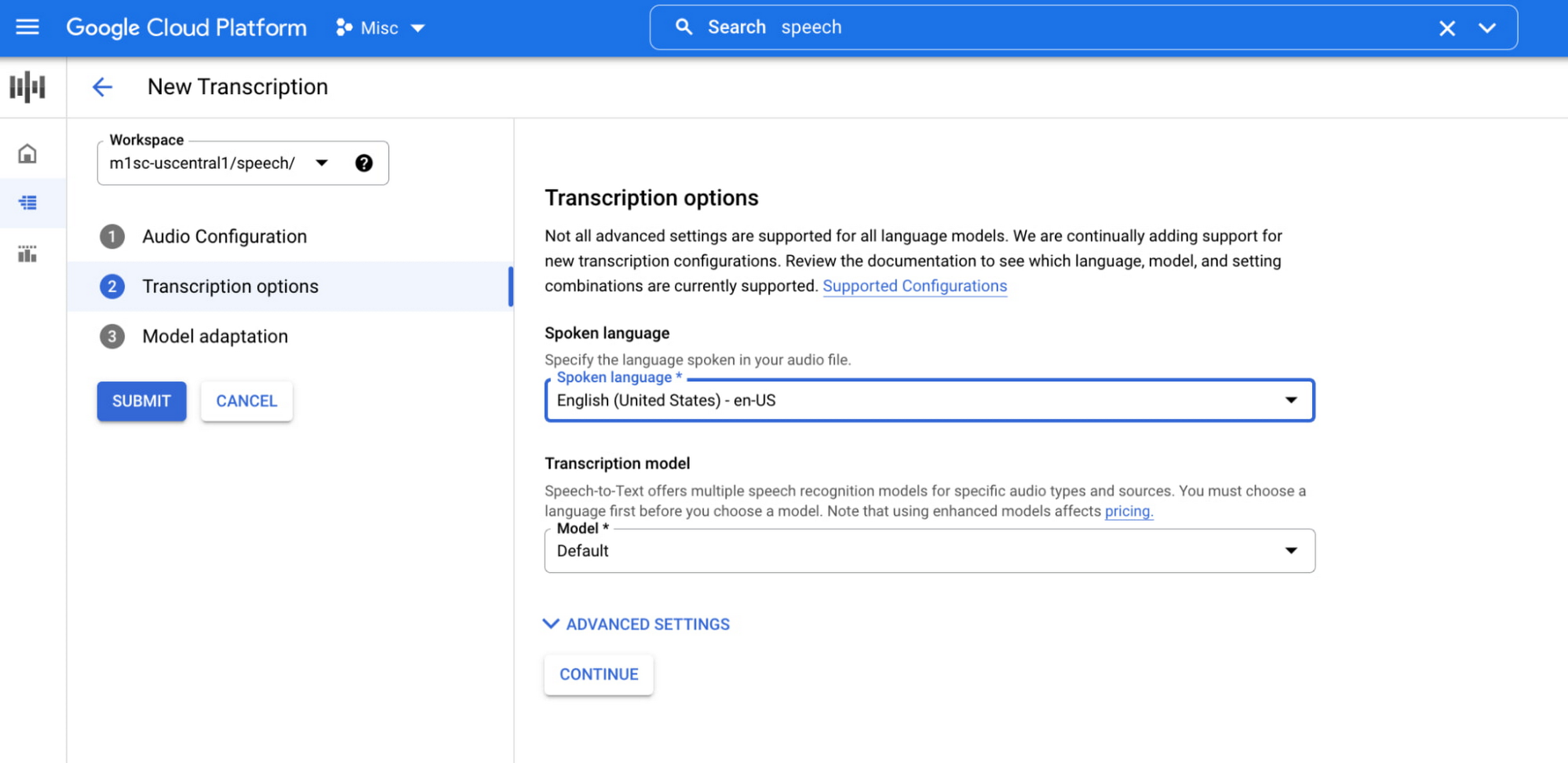
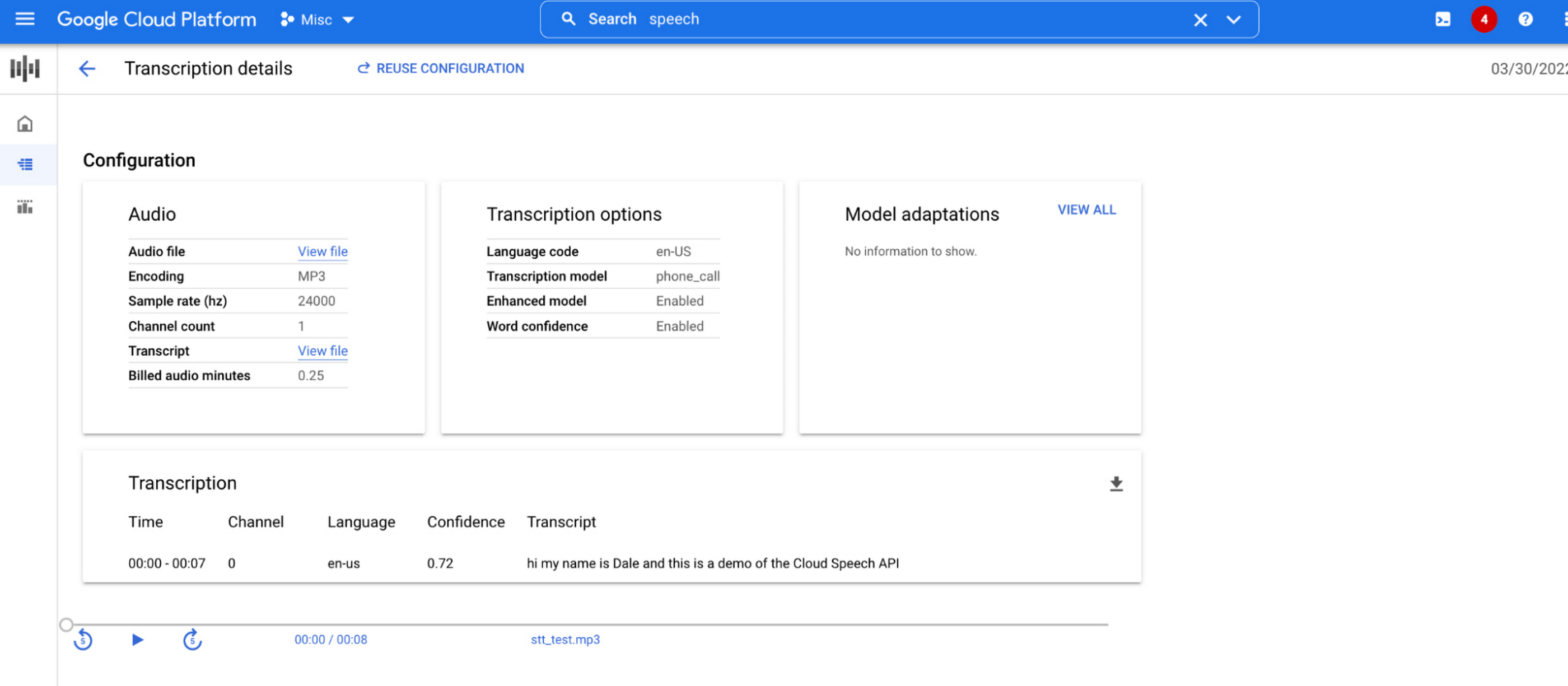
As these use cases show, AI is helping find efficiencies and solve real-world challenges. At Google, we believe this opportunity carries with it the responsibility to build and integrate AI products that can work for everyone. Google Cloud’s AI products have responsibility built in by design guided by our AI Principles–however we know our products and services don’t exist in a vacuum. Successful AI requires that organizations take into account the use case, the training data and societal context. To learn more about our Responsible AI governance process, click here.
Ready to start building speech-powered apps? Check out the Speech-to-Text API on Google Cloud and get started with your free trial today!